Redis知多少?

Redis知多少?
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/5008d57f.html
前言
你好,我是测试蔡坨坨。
我们都知道,目前的互联网系统几乎都会用到缓存。而在众多技术中,Redis以其卓越的性能和多功能特性,成为技术选型中最受欢迎的选择之一,在项目中几乎无处不在。
当然,Redis的应用场景不仅仅是缓存。其快速的读写速度、丰富的数据结构和强大的扩展功能,在各种应用场景中表现出色。例如:分布式锁、实时数据分析、消息队列、会话管理、限流等多种应用场景。
所以,作为测试,Redis几乎是100%需要掌握的技术点。
本系列将以问答的形式,列出关于Redis不得不知道的关键问题,进而全面掌握这项强大的技术。通过深入解析这些问题,将揭示Redis的核心原理和最佳实践,指导我们在实际项目中更高效地使用Redis。并从测试的角度,结合实例说明Redis在测试过程中的具体应用。
在往期文章中,我们已经讨论过关于Redis缓存击穿、雪崩和穿透的问题,可参考:
Q&A
Redis常见的数据结构有哪些?
Redis常见的数据结构主要有五种,分别为String、Hash、List、Set、Zset。
随着Redis版本的更新,后面又新增了四种高级数据类型,BitMap(2.2版)、HyperLogLog(2.8版)、GEO(3.2版)、Stream(5.0版)。
| 结构类型 | 存储的值 | 读写能力 | 应用场景 |
|---|---|---|---|
| String(字符串) | 最基本的数据类型,一个键对应一个值; 值可以是字符串、整数或浮点数; 最大值的大小为512MB |
对整个字符串或字符串的一部分进行操作; 对整数或浮点数进行自增或自减 |
缓存对象、计数器、分布式锁、分布式session等 |
| Hash(哈希) | 类似于传统的哈希表,键值对集合; 每个键对应一个哈希表,哈希表内部是键值对; 适合存储对象,如用户信息 |
添加、获取、删除单个元素 | 缓存对象、购物车等 |
| List(列表) | 双向链表,支持从两端推入和弹出元素; 按插入顺序排序,可以通过索引访问; 可以用作队列或栈 |
对链表的两端进行push和pop操作,读取单个或多个元素; 根据值查找或删除元素 |
阻塞队列、消息队列(有两个问题:1.生产者需要自行实现全局唯一ID 2.不能以消费组形式消费数据)等 |
| Set(集合) | 无序集合,元素唯一 | 是否存在、添加、删除; 计算交集、并集、差集等 |
点赞、共同关注、收藏等 |
| Sorted Set/Zset(有序集合) | 类似于集合,但每个元素会关联一个得分 | 字符串成员与浮点数分数之间的有序映射; 元素的排列顺序由分数的大小决定; 添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
排行榜 |
| 结构类型 | 应用场景 |
|---|---|
| BitMap | 主要有0和1两种状态,可以用于签到统计、用户登录态判断等 |
| HyperLogLog | 海量数据基数统计,有一定的误差,可以根据场景选择使用,常用于网页PV、UV的统计 |
| GEO | 存储地理位置信息,比如百度地图、高德地图、附近的人等 |
| Stream | 消息队列,相比于List多了两个特性,分别是自动生成全局唯一消息ID和支持以消费组形式消费数据 |
Redis的应用场景?
列举几个常见的场景:
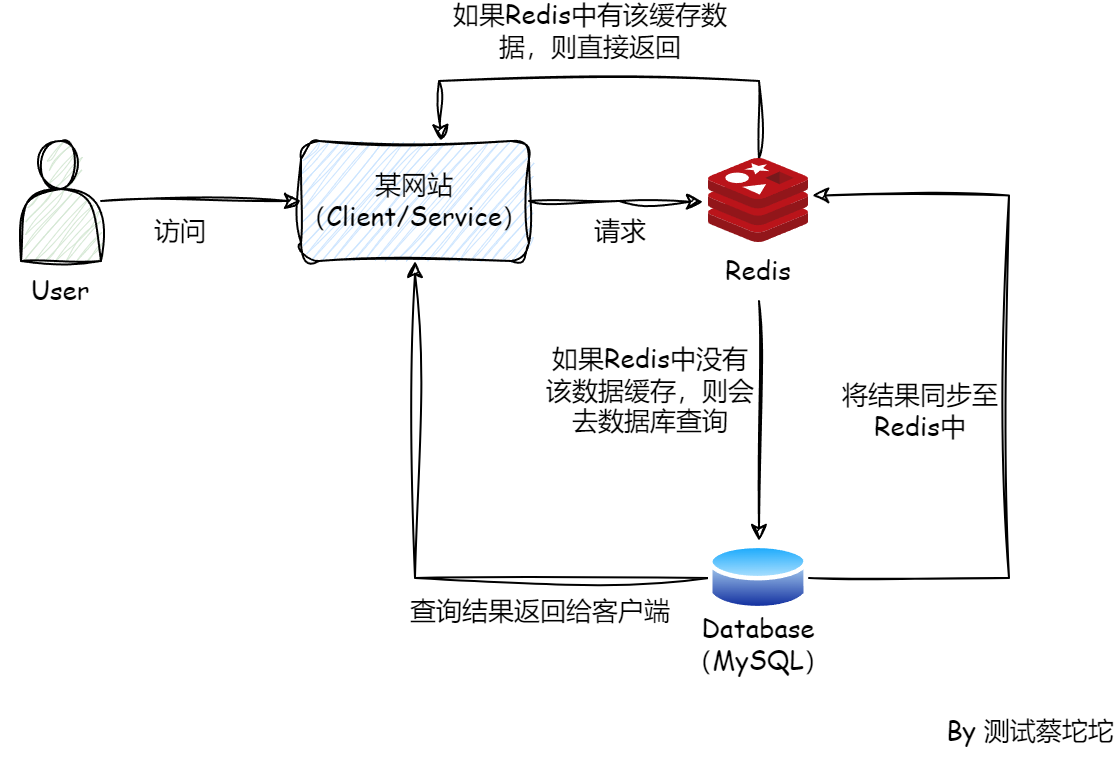
缓存
Redis是基于内存的,读写速度比MySQL基于磁盘的方式要快很多,所以其作为热点数据的缓存是非常合适的。使用Redis缓存可以极大地提高应用的响应速度和吞吐量。

测试应用:
在缓存数据的场景中,如token缓存、配置信息缓存等,如果我们需要进行重复测试,就可以在Redis中找到对应的键并删除其值。这样可以确保每次测试都在相同的初始状态下进行,以避免数据污染和测试结果不准确。(如何删除?①使用命令
redis-cli keys "token:*"查找键,再使用redis-cli del "token:caituotuo"删除键 ②使用Python脚本,redis库 ③使用客户端连接redis,如Redis Desktop Manager)分布式锁
本地锁(synchronized、lock)在很多时候已经满足不了我们的需求,特别是现在大部分企业都使用微服务架构,不同实例之间的锁需要依赖外部系统进行一致性锁定,因此就需要用上分布式锁。
Redis就是一个很好的外部系统,它基于缓存使得加锁非常高效,天然的过期机制可以很好地避免死锁的发生,且配合redission这种封装好的类库,使得使用起来也非常简便。
关于锁可以参考往期文章:8 分钟搞懂 Java 中的各种锁
消息队列
在一些简单场景,也可以利用Redis来实现消息队列。例如:使用列表的
lpush(从左边插入)实现消息的发布,rpop(从右边吐出)实现消息的消费。也可以使用Redis5.0之后引入的stream这个数据结构来实现消息功能。但是,使用Redis实现消息队列肯定比不上正常的消息队列中间件,例如无法保证消息的持久化,即使有AOF(Append-Only File)和RDB(Redis Database)也无法保证消息一定不会丢。
在大型系统或正常的业务场景下,如果要使用消息队列还是得用RabbitMQ、RoketMQ、Kafka等,不推荐使用Redis来实现。
实时系统
由于Redis高性能的特性,其经常被用于构建实时系统,例如:抽奖、秒杀等,最常见的还有
排行榜的实现,其可以使用Redis的Zset数据结构,根据用户的分数、时间等参数构建一个实时的排行榜。计数器
Redis由于其单线程执行命令的特性,实现计数器非常方便,不会有锁的竞争。像文章的点赞数量就可以使用Redis实现。
再如一些
海量数据的统计,例如大网站的访问统计、日活月活等,适合使用Redis提供的高级数据结构HyperLogLog。它基于基数估算算法实现,优点就是所需的内存不会随着集合的大小而改变,因此很适合大规模数据集统计的场景,不过它的统计值是不精确的,有一定的误差,但是在海量数据场景,这些误差一般是可以接受的。

Redis主从实现原理?

主从架构可以实现读写分离。
写操作可以请求主节点,而读操作只请求从节点,这样就能减轻主节点的压力。

整个主从集群仅主节点可以写入,其他从节点都通过复制来同步数据,这样就能保证数据的一致性。
并且对读请求分散到多个节点,提高Redis的吞吐量,从一定程度上也提高了Redis的可用性。
主从复制原理
Redis主从之间的复制主要有两种数据同步方式,分别是全量同步和增量同步。
① 全量复制

流程:
- 从节点发送
psync ? -1,触发同步。(runid指的是主服务器的ID,从节点第一次同步不知道主节点的ID,于是传递了一个“?”;offset为复制的进度,第一次同步值为-1) - 主节点收到从节点的psync命令之后,
发现runid没有值,判断是全量同步,返回fullresync并带上主服务器的runid和当前复制进度offset,从服务器会存储这两个值。 - 主节点
执行bgsave生成rdb文件,在rdb文件生成过程中,主节点新接收到的写入数据命令会存储到replication buffer中。 - rdb文件生成完毕后,主节点将其发送给从节点,从节点清空旧数据,加载rdb数据。
- 等到从节点中rdb文件加载完成后,主节点将replication buffer缓存的数据发送给从节点,从节点执行命令,保证数据的一致性。
待同步完成后,主从之间会保持一个长连接,主节点会通过这个连接将后续的写操作传递给从节点执行,来保证数据的一致性。
② 增量同步

主从服务之间的网络可能不稳定,如果连接断开,主节点部分写入操作未传递给从节点执行,主从数据就不一致了。
此时有两种解决方案,一种是选择再次发起全量同步,但是全量同步数据量较大,非常耗时。因此Redis在2.8版本引入了增量同步,仅需把连接断开期间的数据同步给从节点即可。
repl_backlog_buffer是一个环形缓冲区,默认大小为1M。主节点会将写入命令存到这个缓冲区,但大小有限,待写入的命令超过1M后,会覆盖之前的数据,因此是环形写入。
增量同步也是psync命令,如果主节点判断从节点传递的runid和主节点一致,且根据offset判断数据还在repl_backlog_buffer中,则说明可以进行增量同步。
于是就去repl_backlog_buffer查找对应的offset之后的命令数据,写入到replication buffer中,最终将其发送给slave节点。slave节点收到指令之后执行对应的命令,一次增量同步的过程就完成了。
如果根据offset判断数据已经被覆盖了,此时只能触发全量同步。因此可以调整repl_backlog_buffer大小,尽量避免出现全量同步。
replication buffer 和 repl_backlog_buffer 的区别:
- 不同的从节点同步速度不一样,主节点会为每个从节点创建一个replication buffer,它用于实时传输写命令,且大小是动态的,因为对于同步速度较慢的从节点服务器,需要更多的内存来存储数据。
- 虽说replication buffer没有明确的大小限制,但是可以通过
client-output-buffer-limit slave 256mb 64mb 60(该配置表示如果从服务器的输出缓冲区大小超过256MB,且在60秒内未恢复到64MB以下,Redis将断开与从服务器的连接)间接控制,该参数可以设置不同类型客户端(普通、从服务器、发布订阅)的输出缓冲区限制。当缓冲区大小超过限制时,Redis会断开与客户端的连接。
Redis为什么这么快?
主要有三方面原因:
- 存储方式
- 优秀的线程模型和IO模型
- 高效的数据结构
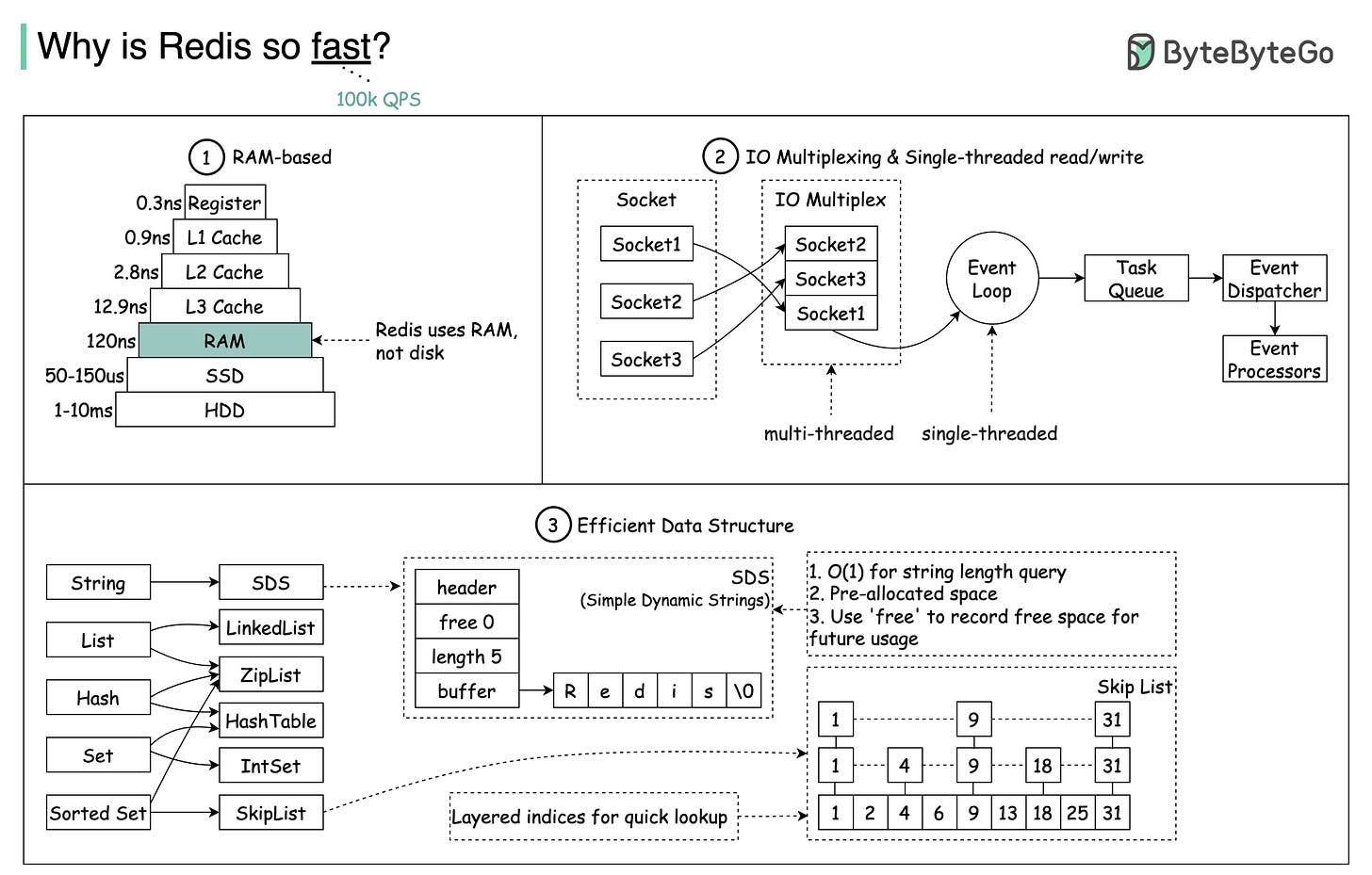
存储方式
Redis的存储是基于内存的,直接访问内存的速度是远远大于访问磁盘的速度的。
一般情况下,计算机访问一次SSD磁盘的时间大概是50150微秒;如果是传统的硬盘,需要的时间更长,大概是110毫秒;而访问一次内存的时间大概是120纳秒。因此,可见访问的速度差了快一千倍左右。
优秀的线程模型和IO模型
Redis使用单个主线程来执行命令,不需要进行线程切换,避免了上下文切换带来的性能开销,大大提高了Redis的运行效率和响应速度。
Redis采用了I/O多路复用技术,实现了单个线程同时处理多个客户端连接的能力,从而提高Redis的并发能力。
不过,Redis并不是一直都是单线程的,从4.0开始,Redis引入了Unlink这类命令,用于异步执行删除等操作,还有在6.0之后,Redis为了进一步提升I/O的性能,引入了多线程机制,利用多线程机制并发处理网络请求,从而减少Redis由于网络I/O等待造成的影响。
高效的数据结构
Redis本身提供了丰富的数据结构,比如:String、Hash、Zset等,这些数据结构大多操作的时间复杂度都是O(1)。
Redis集群是什么?
简单来说,Redis集群就是通过多台机器分担单台机器上的压力。
当单机Redis缓存的数据量太大,请求量也高,这个时候,就可以采用Redis集群(Redis Cluster)的方案。
Redis集群会将数据分片存储到多台Redis上,多个Redis实例都可进行读写操作(每个分片内部还是有主从结构,目的是为了提高集群的可用性)。
集群内每个节点都会保存集群的完整拓扑信息,包括每个节点的ID、IP地址、端口、负责的哈希槽范围等,它们直接通过Gossip协议保持通信,会周期性地发送PING和PONG消息,交换集群信息,使得集群信息得以同步。
Redis集群分片原理
Redis集群会将数据分散到16384(2^14)个哈希槽中,集群中的每个节点负责一定范围的哈希槽。
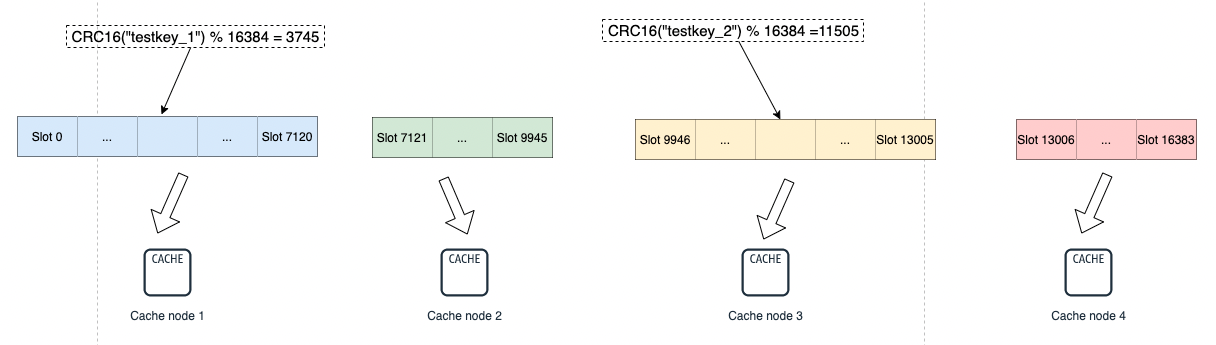
每个节点会拥有一部分的槽位,然后对应的键值会根据其本身的Key,映射到一个哈希槽中:
- 根据键值的Key,按照CRC16算法计算一个16bit的值,然后将16bit的值对16384进行取余运算,最后得到一个对应的哈希槽编号。
- 根据每个节点分配的哈希槽区间,对应编号的数据落在对应的区间上,就能找到对应的分片实例。
Redis客户端可以访问集群中任意一台实例,正常情况下这个实例包含这个数据。
但如果槽被转移了,客户端还未来得及更新槽的信息,当前实例没有这个数据,则返回MOVED响应给客户端,将其重定向到对应的实例。
为什么哈希槽节点的数目是16384?
首先是消息大小的考虑,正常的心跳包需要带上节点完整配置数据,心跳还是比较频繁的,所以需考虑数据包的大小,如果使用16384数据包只要2k,如果使用65535则需要8k。
实际上槽位信息使用一个长度为16384位的数组来表示,节点拥有哪个槽位,就将对应位置的数据信息设置为1,否则为0。
集群规模的考虑,集群不太可能会扩展超过1000个节点,16384够用且使得每个分片下的槽位又不会太少。
Redis如何实现分布式锁?
如果是基于Redis来实现分布式锁,则需要利用SET EX NX命令 + lua脚本。
加锁:
1 | SET lock_key unique_value EX expire_time NX |
解锁(使用lua脚本):
1 | if redis.call("GET",KEYS[1]) == ARGV[1] then |
lock_key:就是锁的key键。
unique_value:是客户端生成的
唯一标识,为了防止被别的客户端给释放了。假设没有这个唯一值:
- 客户端A加锁成功,然后执行业务逻辑,但执行的时间超过了锁的过期时间。
- 此时锁已经过期被释放了,客户端B加锁成功。
- 客户端B执行业务逻辑。
- 客户端A执行完了,执行释放锁逻辑,即删除锁。
此时客户端B就会一脸懵逼,我还在执行呢,锁怎么就被别人释放了??
所以每个
客户端/每个线程加锁时,需要设置一个唯一标识,比如uuid,防止锁被别的客户端误释放。因为需要先判断
锁的值和唯一标识是否一致,一致后再删除释放锁,这里就涉及到两步操作,所以需要使用lua脚本才能保证原子性,这也是为什么释放锁要使用lua脚本的原因。锁需要有
过期机制,假设某个客户端加了锁之后宕机了,锁没有设置过期机制,会使得其他客户端都无法抢到锁。EX expire_time就是设置锁的过期,单位是秒;还有PX也是过期时间,单位是毫秒。在2.6.12版本之前只有
SETNX,即SET if Not eXists,它表示如果key已存在,则什么都不会做,返回0,如果不存在则会设置它的值,返回1。那个时候,SETNX和过期时间的设置就无法保证原子性,如果客户端在发送完SETNX之后就宕机了,还没来得及设置过期时间,一样会导致锁不会被释放。
因此在2.6.12版本之后,优化了SET命令,使得可以执行SET EX PX。
扩展:如何进行幂等性设计?避免项目中出现多笔重复的交易订单
数据库唯一约束
可以将订单号作为数据库的主键或唯一索引,这样一来,数据库就会拒绝重复插入的情况,避免重复订单。
分布式锁
可以利用分布式锁来避免多个请求同时处理同一笔订单的情况,比如使用Redis来实现:
1
2
3
4
5
6
7
8
9
10
11
12String lockKey = "order_lock_" + orderNo;
boolean isLocked = redisTemplate.opsForValue();
if (isLocked){
try {
// 处理订单逻辑
} finally {
redisTemplate.delete(lockKey);
}
} else {
// 已有请求在处理订单
}PS:这里设置lockKey时使用
"order_lock_" + orderNo这种以订单号的维度加锁,避免同笔订单多次插入的同时锁的粒度也足够细。假设仅使用
"order_lock"作为lockKey,那么下单方法的并发度就是1,严重影响性能,会导致请求阻塞引发系统崩溃。




