彻底搞懂Redis击穿、雪崩、穿透(下)

彻底搞懂Redis击穿、雪崩、穿透(下)
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/523ea512.html
前言
你好,我是测试蔡坨坨。
早起的鸟儿有虫吃,现在是北京时间2024年1月8日08:00:00。
贰零贰肆年的第一篇Blog,也是Redis缓存三大问题的第三篇,继第一篇发布已经过去一个半月的时间,期间还有热情的小伙伴催更(hahaha~
对于缓存的击穿、雪崩、穿透,是大家再熟悉不过的话题,也是面试高频题,网上也有无数相关的资料。至于为什么还写这个话题呢?因为缓存的这三大问题看似很平常简单,其实背后涉及到的知识点是可以有很多的,很多时候我们不应该仅仅拘泥于问题答案本身,而是能够联想到问题所置身的场景,理解整个系统的环境,从一个更高的维度去看这个系列,去理解设计的原由和思路。
只有这样,我们才能更好地面对这个不断变化的时代。
前面两篇分别聊了缓存的击穿和雪崩,其中还涉及到了锁相关的话题,所以顺便盘点了下Java中的各种锁,而本篇我们就来讨论缓存的最后一个问题——缓存穿透。
往期文章:
缓存穿透
很多同学会把缓存穿透和缓存击穿搞混,主要是名词方面的混淆,其实只要关注意思即可,就很容易区分。
什么是缓存穿透呢?
举个简单栗子,作者开发了一个非常火爆的网站,动了某些人的蛋糕,然后遭到疯狂的攻击,攻击手段就是采用缓存穿透,大家都知道数据库的主键是从0开始递增的,也就不存在负数的情况,那么黑客就利用这一点,不断利用ID小于0的参数向服务器发送请求,系统首先会去查Redis缓存,缓存中没有查到数据,就会去查数据库,数据库也不存在ID小于0的数据,所以Redis中也永远也不会有该数据,就会造成请求不断打到数据库上,中间Redis层并不能拦截这样的数据,Redis直接被这种数据穿透,直击数据库。
缓存穿透和击穿的区别就是:
- 缓存击穿:数据库里有数据
- 缓存穿透:数据库里没有数据
所以,缓存击穿可以规避是因为Redis缓存数据失效,而数据库里有数据,只要把数据库里的数据更新到缓存中,就可以解决缓存击穿的问题。
但是,缓存穿透意味着这个数据在数据库里没有,就不可能把数据刷到Redis缓存中,因此只要有人来查询,缓存中一定查不到,一定会打到数据库上。
假设有很多这样的恶意用户故意去查询数据库里面没有的记录,此时Redis起不到屏障的作用,并发查询必定会打到数据库上。
那么,既然知道了缓存穿透的原因,要想解决就必须想办法识别出哪些请求的数据是数据库里没有的,然后对这些请求进行过滤。
不妨思考一下,可以用什么办法?
一个比较简单的方法,就是当用户的查询请求直接穿透Redis到达数据库时,无论数据库查询到怎样的结果,空值还是有值,都把这个key缓存到Redis中,对于不存在的数据就用一个特殊的value来表示,比如null,这样下次再用同一个参数来发请求时就不会穿透Redis。
但是,它可能会换不同的参数来请求,这样一来Redis缓存就会存储大量无用的数据,造成空间浪费。一般出现这种情况都不是正常的用户,而是一些恶意用户。
而且这样的数据是无穷尽的,因为我们不可能找出所有数据库中不存在的数据,但是相反,对于数据库中已存在的数据,那就是有限的,我们可以找出所有已存在的数据,这样当请求打过来时,我们就可以判断这个数据是否存在。
但是由于数据量巨大,我们必须用尽量少的时间和空间去对数据已存在做一个判断。正因为Redis内存空间可贵,我们才不能缓存所有的数据,因而才会有查询数据库的操作。所以我们不能直接把完整的数据信息全部搬到缓存中。
既然无法存储完整的数据到缓存中,那么是否可以只存key呢?因为数据的大部分空间都是value占据,key相对于value来说小得多得多,进而使单位范围内的内存能存储更大的信息量。是否可以额外开辟一片集合来专门存储key,这样每次访问数据库前先去集合中查询key是否存在,如果存在再去访问数据库。
哎呦,不错哦!这样,确实可以解决缓存穿透问题,比起存储完整的key和value,只存key确实会节省更多的缓存空间。理论上听起来没什么问题,但现实总是残酷的,假设一台Redis缓存4T的热点数据,key:value=1:99,那么需要缓存的key总量大约是40G,在巨大的数据量面前,这种方法仍然是需要超高的成本。
是否有更节省空间的存储方式呢?计算机最小的存储单位是bit,也许可以用一个位来存储。在讨论如何实现之前,先来看下能节省多少空间,1个key占用1个bit,1个字节能存储8个key,1Mb字节就可以存储800w个key,100Mb就能存储8亿个key。这简直就是把空间利用到了极致。
既然空间的问题解决了,那么新的问题就是如何把一个key和一个bit去对应起来?此时就会联想到哈希映射,每个key通过哈希函数转换成一个数组的下标,然后按键值对存储在HashMap中,而HashSet只存储key,不存储value。
使用哈希映射可以将所有存在的key全部对应到bitmap的每个槽位上,将所有存在的key映射到bit槽位上,然后用1表示,其余部分用0表示。这样当查询的key被映射到0的槽位上,就表示数据不存在,就可以直接返回,进而实现请求数据的过滤。
看似很完美,既解决了空间问题,又保证每个key都映射到槽位上,还会有什么问题呢?
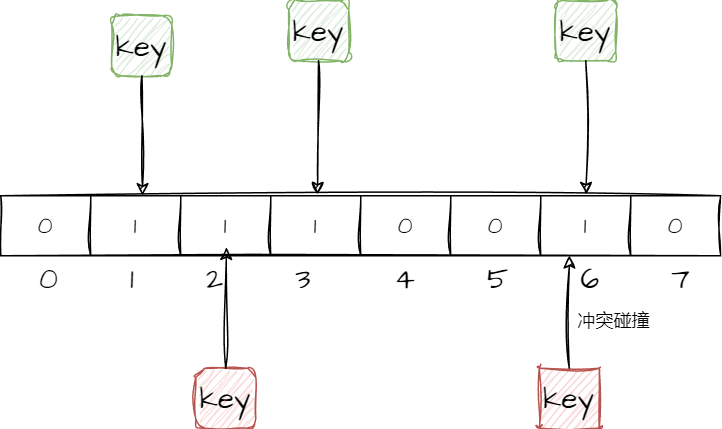
我们都知道HashMap出现冲突时,会用一个链表去连接那些冲突的节点,保证所有的key都完好无缺的存储,不存在不同的key将其他的key挤掉的情况。但是由于此时槽位已经缩减到bit,不可能再追加其他的数据类型,所以就无法用链表解决冲突碰撞的产生,并且由于bit槽位只存0和1,即使发生碰撞,也无法判断原有的信息是什么(只判断值是否存在,而不关心值是什么,也反向说明了安全性非常好),所以这种方法会存在碰撞问题。
并且这个问题是无法被完全解决的,由于要节省空间,每个槽位都被精简到了一个bit,所以能表示的信息也只有0和1两种,无法表示出其他信息,除非增加空间来保存更多的信息,增加1个bit,体积就会翻倍,增加2个bit,体积又翻一倍,那岂不是又回到了最初的问题。
其实很多时候我们是无法找到一个绝对完美的解决方案,正如测试用例一样,我们永远无法做穷尽测试,所以才会有各种测试方法论,等价类、边界值,精准测试等。既然无法完全解决冲突碰撞问题,我们是否可以将碰撞的概率降低呢,而不是完全让冲突碰撞消失。
1970年,一个叫布隆的小伙子就提出了一个解决方案,也就是布隆过滤器。
因为在单次哈希的情况下会产生一定的碰撞,为了降低产生碰撞的概率,布隆就采用多次哈希的方式,每次哈希都往槽位写上1,当来查询一个不存在的key时,就可以进行同样的多次哈希,第一次可能碰巧撞到,得到1,但是后面还有几次就不一定能够碰上了,这样就能降低缓存穿透的概率。
根据具体的需求,调整bitmap的大小以及哈希函数的个数,就可以得到不同的过滤百分比,漏网之鱼就会变得少之又少。
比如“测试蔡坨坨”这五个字要存到布隆过滤器里需要经过的步骤:
- 经过3个哈希函数分别计算出3个哈希值
- 把3个哈希值映射到数组中,假设第一个哈希函数算出1,就会把下标为1的位置改成1,第二个算出3,就会把下标为3的位置改成1,第三个算出6,就会把下标为6的位置改成1
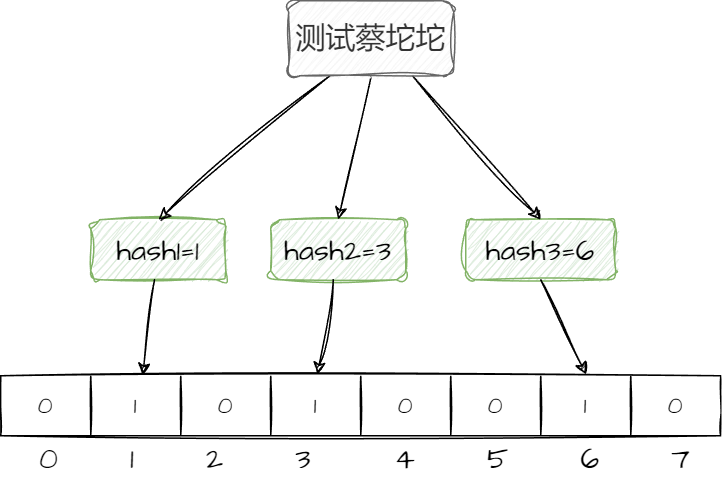
查询的时候必须1、3、6的位置都为1,才表示数据存在,只要有一个位置的二进制数据不是1,那么这个数据就不存在。
布隆算法设计的巧妙之处在于多个哈希函数以及二进制数据必须都是1才能证明数据存在。
不过对于布隆过滤器的使用还是有很多需要思考的空间,例如:布隆过滤器放在哪里合适?
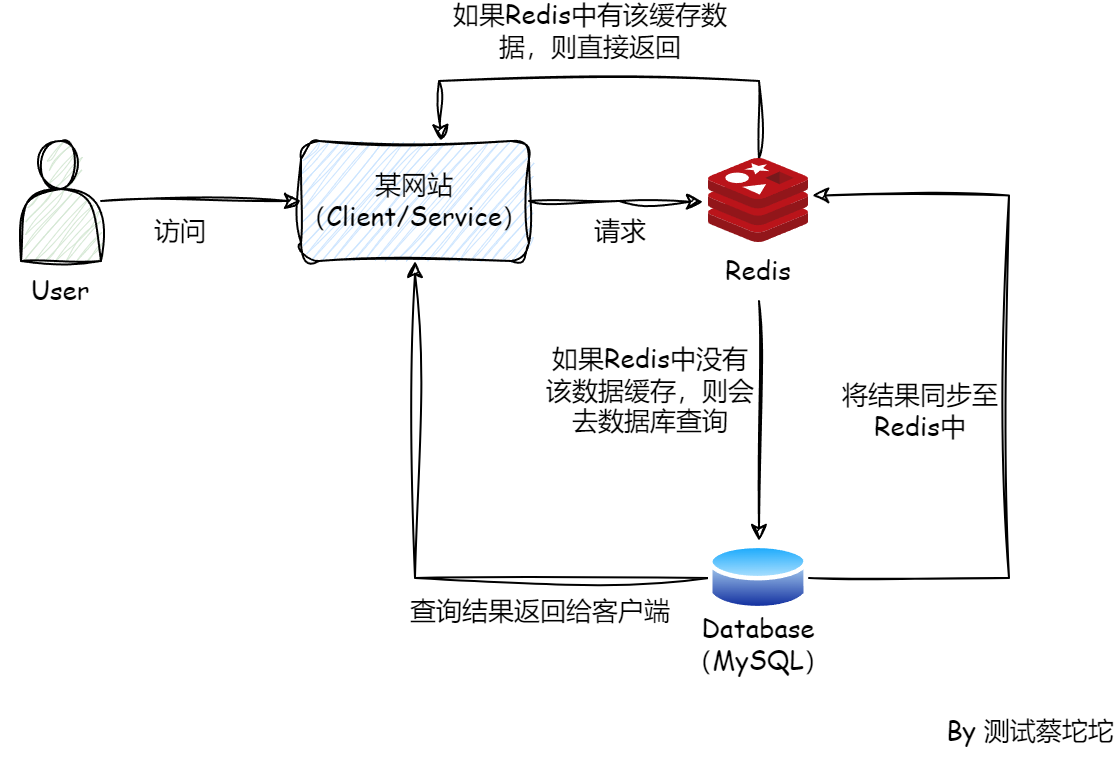
- 放在客户端(Client/Service),每个客户端都
包含布隆算法以及存储一个bitmap来过滤无效的查询请求,这样Redis的压力就会减小。不过,由于是基于JVM的布隆过滤器,所以重启就会失效,而且因为是存储到本地,导致无法应用到分布式场景,也不支持存储大量数据。 - 把算法放到客户端,bitmap存储到Redis上,这样客户端就是无状态的,可以轻松复制。
- 把算法和bitmap都放到Redis上,也就是在Redis中集成这么一模块。这样,客户端又省了代码,能够更加灵活,也省去了重启失效和定时任务维护的成本。但是,由于布隆过滤器外迁到Redis上,会导致网络I/O开销增大,并且性能也会比JVM上的略低。
无论如何,缓存穿透的问题算是有个比较好的解决方案。
但是,看似完美的方案,还是会有缺陷,上面我们讲了布隆过滤器数据的增加和查询,唯独没有说到删除。因为布隆过滤器很难去做删除操作,也就是说只能往里添加数据,无法删除数据。为什么呢?
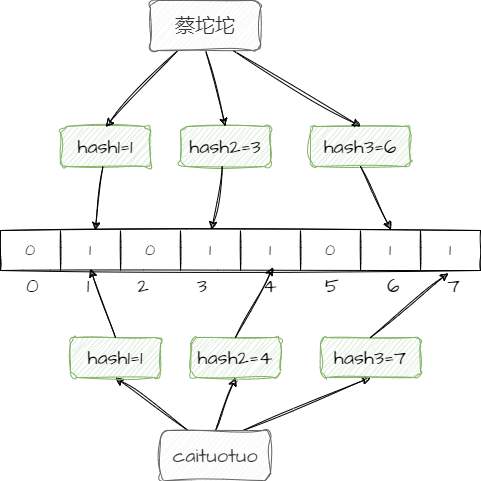
举个栗子,如上图所示,“蔡坨坨”和“caituotuo”这两个数据的第一个哈希函数算出来的值都是1,如果要把“蔡坨坨”这个数据删除,就需要把下标为1的位置改成0,那么就会导致“caituotuo”这个数据也会被删除,因为只要有一个位置不为1,就代表数据不存在,就会导致数据的误删,所以布隆过滤器很难做到删除操作。
因此,对于数据需要频繁增删改的场景,是不太适合用布隆过滤器的。要解决这个问题,可以使用布隆过滤器的加强版,也就是布谷鸟过滤器,它是带删除功能的,以满足动态变化的需求。关于布谷鸟过滤器的使用,我们放在另外的文章中讨论。
布隆过滤器的代码实现,可以使用Google Guava 提供的 BloomFilter 类来实现。
导入依赖:
1 | <dependency> |
布隆过滤器实现+误判率测试:
1 | package top.caituotuo.bloom; |





