彻底搞懂Redis击穿、雪崩、穿透(上)

彻底搞懂Redis击穿、雪崩、穿透(上)
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/d442a007.html
你好,我是测试蔡坨坨。
缓存雪崩、穿透以及击穿,作为老生常谈的问题,也是面试八股文中经常被提及的话题。因为目前的互联网系统没有几个不需要用缓存的。然而,对于缓存的这三个问题,很多人只是单纯的背过答案(比如布隆过滤器、分布式锁等),却少有人能够清楚地理解其思路。本文旨在深入浅出地探讨和分析这三大缓存问题。强调的是,真正有价值的不仅是答案本身,更是解答背后的思考和推导过程。如果能够理解这些问题的根本原因,才能更好地应对类似的挑战。
在探讨这三个问题之前,有必要先了解一下整个系统的架构。
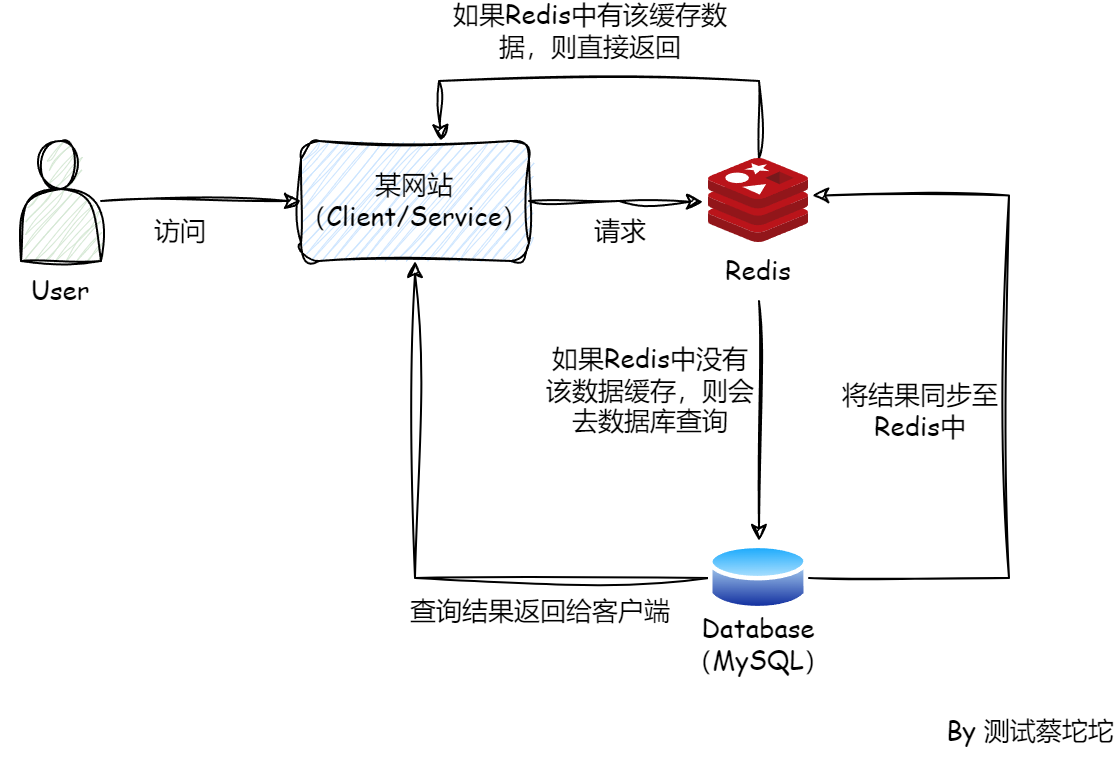
首先最前面的是用户访问我们的网站,这个网站也就是客户端,站在外围的层面来看,客户端其实就是一个Service服务,而这个服务可能只是微服务群体中的一个,其中还有许多其他的服务,微服务再往前延伸就是网关,可以是业务网关,而网关再往前必定有流量分发,负载均衡,例如NGINX等,如果项目足够大,可能还涉及CDN把各地的流量分离。
客户端在很多情况下,必然会去访问我们的Redis缓存,如果缓存中有数据,则直接返回,如果缓存中没有数据,Redis就会去请求数据库,查询到数据之后,数据库会把查询到的结果返回给客户端,同时会把数据同步到Redis缓存中。所以,Redis的后面必然有一个数据库,比如MySQL。
从中可以看出,真正的流量其实是来自用户,只有用户的数量足够多,才会有所谓的高并发,而我们的系统从前往后一层一层的过滤掉各种各样的请求,最后抵达数据库的只有很少的一部分请求。这也是架构师在横向看项目时需要做的事情。
在整个系统中,Redis作为缓存,扛住并过滤掉了很多的请求,使得数据库的压力变得很小,节省了很多磁盘i/o的操作。
缓存击穿
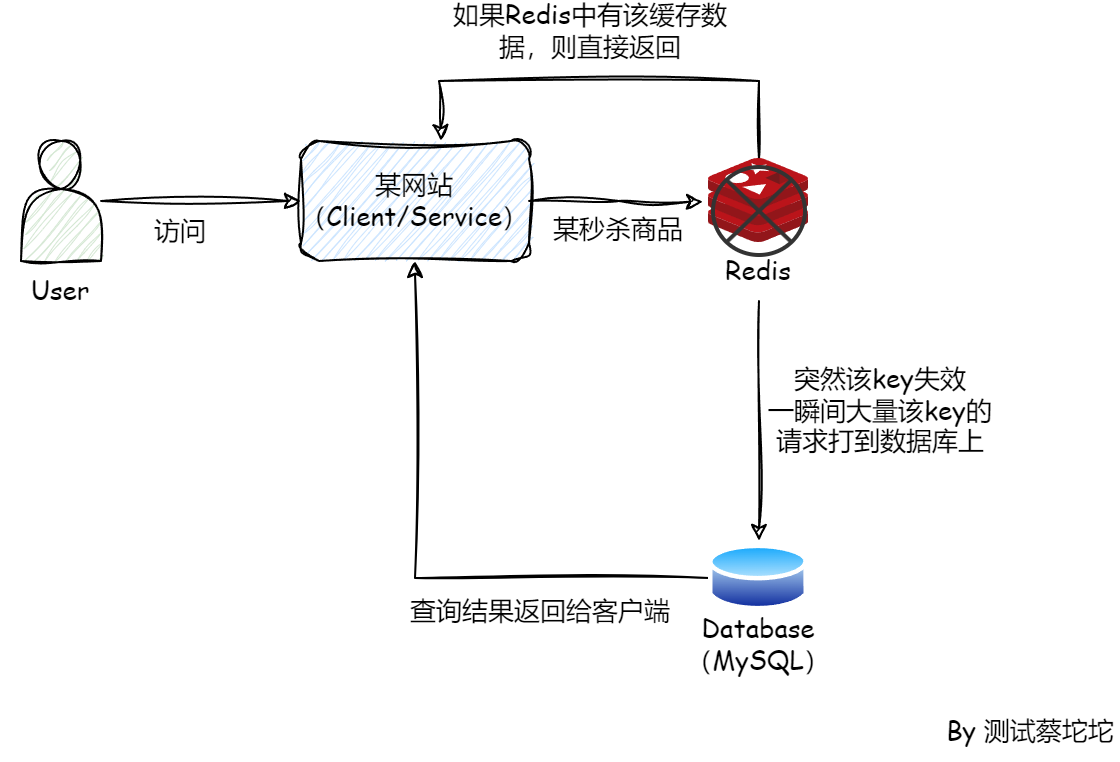
所谓“缓存击穿”通俗的解释就是某个热点数据,某一时刻在缓存中失效,进而大量的请求打到数据库上,就像被击穿了一样。说白了就是某个数据,数据库中有,缓存中没有,一瞬间大量该key的请求打到数据库上,导致数据库被打垮。最常见的场景就是秒杀商品。
Redis作为缓存,要么会给key设置过期时间,在一段时间后清除,要么就是被LRU(Least Recently Used,最近最少使用淘汰算法)和LFU(Least Frequently Used,最不经常使用淘汰算法)清除冷数据。
所以说只要作为缓存,就会存在这种情况,某个key在某一时间,要么过期,要么被算法自动清除,然后突然有人来访问它,就像Redis被打了一个窟窿,击穿过去,直达数据库。
那么如何规避这件事情呢,首先必须承认的就是肯定发生了高并发,如果一个系统本身没什么流量,打到数据库就打到数据库呗,完全不是问题。
那么在高并发情况下,一个key过期了,如何解决成千上万的并发蜂拥而至呢?
首先,我们想到的就是让这个缓存永远不过期,这也是网上给出最多的答案,为什么大部分人会给出这个答案呢?因为存在缓存击穿问题的,光并发量就打败了99%的企业,所以真正有实际场景去解决缓存击穿问题的少之又少,也只能停留在纸上谈兵的阶段,加上大量的博客都这么说,当然也就顺理成章。
显然,这个答案肯定是不好的,那么为什么不好呢?
因为对于一个需要解决缓存击穿问题的企业,他们的业务量一定是普通人无法想象和企及的。正因为他们的数量巨大,所以才需要缓存,而Redis缓存是基于内存的,一个单点一般不会分配过大的内存,即便是集群,所能存储的数据量也是有限的。因此Redis不可能把全部的数据都存入内存,也没有企业可以用内存存储所有的数据。
既然如此,那我只存储热点数据就行了啊,但什么是热点数据呢,在生产环境中,热点数据是时时刻刻都在变化的,虽然可以做一些预估,但是并不能保证预估到多少,例如微博热搜,明星的热搜词总是出其不意攻其不备,因此数据是流动的。在真实场景中,也不可能由人去评估所有的热点数据,而是实时流动的,系统缓存自动过滤掉那些冷门的数据,然后又缓存起新的热点数据。
所以Redis不可能让key永远不会过期,由于热点数据不断变化,Redis必须时刻在淘汰旧数据,缓存入新的数据。
第二种流行的解决方案就是加锁,大致有以下三种方案。
- synchronized加锁
- ReentrantLock.tryLock(),若缓存中没有数据,尝试加锁,抢到锁的那个线程就去查数据库,抢不到就先睡一会儿
- Redis的命令setnx(),只有一个线程能设置成功,也就是能加到锁,只有加到锁,才能去读数据库,然后存入Redis,其他则等待一会儿,再去Redis取
虽然,加锁确实可以解决问题,但是也会衍生出一些其他的问题,我们一个一个来分析。
前面说到对于缓存击穿的情况,肯定是高并发场景,因此查Redis或MySQL肯定不是单台Tomcat进程,在多台Tomcat情况下,一把Java锁是不可能锁住整个集群的。
而且synchronized一旦加锁,是不可撤回的,所以使用synchronized加锁,会导致所有读Redis缓存的线程也被加锁,系统一启动就会被流量击溃,严重的话会导致系统瘫痪。
虽说ReentrantLock.tryLock()加锁,成功的去读数据库,失败的睡眠一段时间,看似解决问题,但是问题也随之而来。一个Java锁,最多只能够锁一个JVM进程,对于集群来说,去Redis读取数据,可能不仅仅只是Java进程,像Nginx也可以直接访问Redis和MySQL。
所以,解决缓存击穿问题,还需要涉及分布式锁的概念。
这里我们使用Redis的方式来解决,当一个key失效,无论是过期还是被LRU/LFU剔除,假设有1w个请求来访问这个key,然后它们会先查询Redis,发现Redis中没有这个key,对应的往Redis用setnx()设置一个key,表示一把锁,接着只有一个线程设置成功去读取数据库,写回Redis,其他的9999个线程休息一会儿再去访问Redis。而这里休息的时间大约等于从数据库取出数据的时间,需要根据压测以及线上环境的情况,给出一个合理的值。
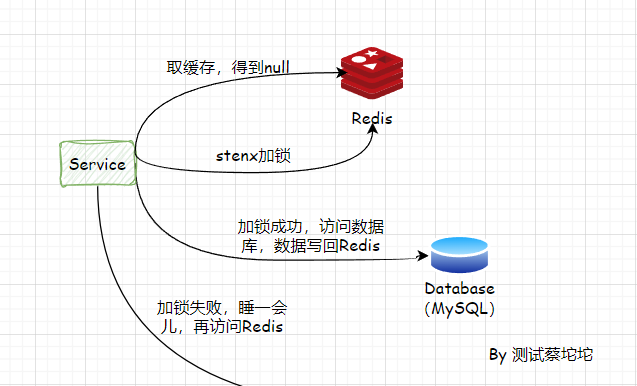
看似合理的解决方案,那么还会有问题吗?答案是肯定的。
假设一堆请求去访问Redis,发现缓存中没有数据,一堆并发开始尝试加锁,最后获取到锁的线程只有一个,其他都失败,此时获取到锁的那台机器断电了,其他线程一直等待,始终没有等到锁被释放或者数据重新写入Redis。
这就是分布式锁种常见的加锁进程死亡问题,导致锁无法被释放,于是就产生了死锁。
既然是常见的问题,那么肯定有解决方案。例如另起一台集群,专门负责监管锁的获取和释放,一旦发现死锁,监管集群就负责将其释放,缺点就是成本高昂。
还有就是利用Redis设置过期时间,保证宕机后,锁也能在超时后自动释放。
那么,这会儿应该没有问题了吧,当然不是,新的问题又来了,假设获取到锁的线程还没来得及设置过期时间就挂了,此时其线程还得一直等着,始终等不到锁释放或Redis被重新存入数据,又是死锁。
又该如何解决这个问题呢?首先明确问题,也就是加锁和设置过期时间是两个步骤,非原子性,那么就将这两个步骤搞成原子操作呗。但是Redis并没有直接的api可以实现既setnx又设置过期时间,那么又该如何处理呢?此时就需要用到Redis事务的概念,Redis的事务与MySQL事务不同的是不支持回滚,虽然不支持回滚,但是可以保证事务中的命令要么全部被执行,要么全部不执行。这样,就可以保证不会发生死锁的情况。
这会儿死锁问题解决了,但是引入了新的问题,那就是超时问题。
假设读取数据库的时间很慢,还没结束,锁就被释放,此时第二个线程也拿到了锁,开始它的操作,然后第一个线程结束,此时所有其他线程应该可以访问数据库,但是由于第二个线程加了锁,导致他们得额外等第二个线程去释放。这样一来就会增加等待时间,如果再加几次锁过程,响应时间就会更长,或直接导致超时断开。
锁的超时时间设置过短,锁就容易被其他线程抢过去,设置时间过长,可能导致时间阻塞变长。
那么又该如何解决超时问题呢?普遍的做法就是引入多线程,加锁后,由于锁会有过期时间,而又无法保证在执行结束前锁不会过期,那么我们就可以采用多线程的方案,让锁每隔一段时间重新设置它的超时时间。
实现过程就是一个手速快的线程抢到了锁,设置了过期时间,执行业务操作,然后再启另一个线程来监控锁的时间,一旦发现快过期了,但是业务还未结束,则重新设置过期时间,周而复始,保证业务未完成,锁不会过期。
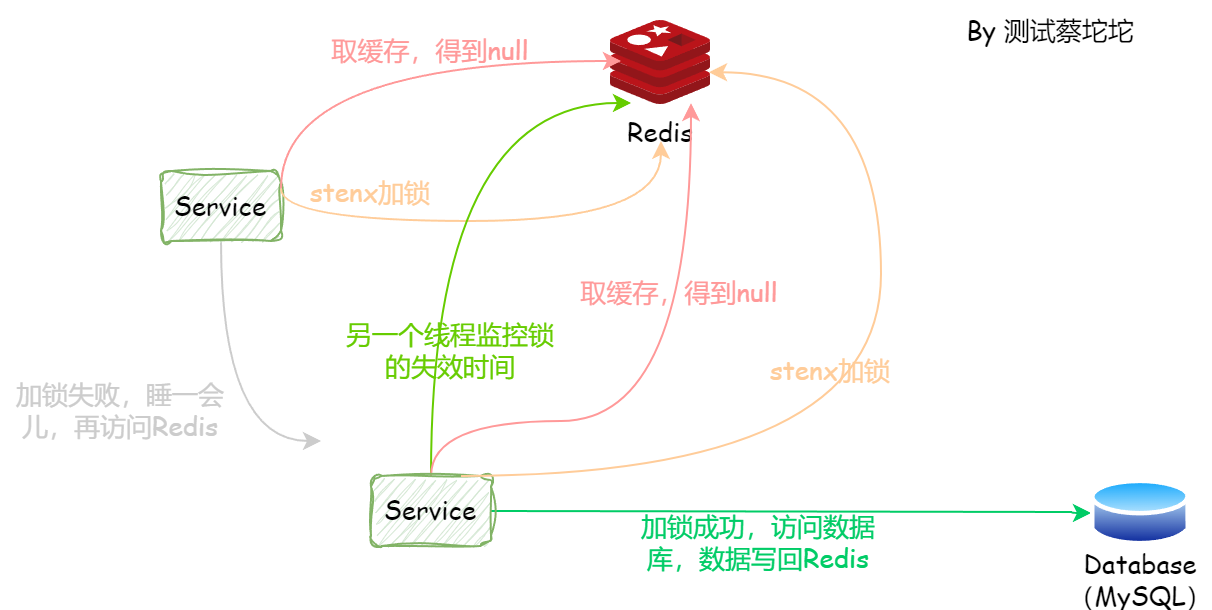
于是,缓存击穿的问题就得以解决。
一顿操作猛如虎,只为解决小小的缓存击穿问题。回过头来看,以上问题都是在Redis是单节点实现的基础上。也就是说我们对这个key的操作都是在一台Redis上,没有同时牵扯到其他的Redis,只要这个Redis不挂,那么就不存在问题,要是Redis挂了,那就不是缓存击穿的问题了,那就是系统高可用问题了。例如Redis的主从,哨兵监控,来保证Redis挂了之后,能立刻有Redis前来替补。




