搭建一个本地AI知识库需要用到哪些技术栈?

搭建一个本地AI知识库需要用到哪些技术栈?
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/5008d57f.html
前言
你好,我是测试蔡坨坨。
随着AI热度愈发火热,越来越多的产品在AI的“赋能”下不断革新和进化。
AI技术的飞速发展不仅改变了人们的生活方式,也大大提升了各行各业的生产效率和创新能力。
在此背景下,我们不妨自己动手丰衣足食,搭建一套属于自己本地的AI ChatBot?顺便学习下“高大上”的AI技术,亲身体验和把握这股“科技潮流”?
本篇,我们将通过全局的视角来看一下 “基于本地上传的文档进行QA问答” 类似的案例,需要学习哪些知识点以及会用到哪些技术栈。
框架
目前,根据我所了解到的知识,市面上深层次的ChatBot主流实现框架基本都是大同小异。
本地大模型 + LangChain + 前端界面
结合RAG框架:上传本地文件 + 文件切片 + Embedding向量编码 + LLM大语言模型
整体流程图
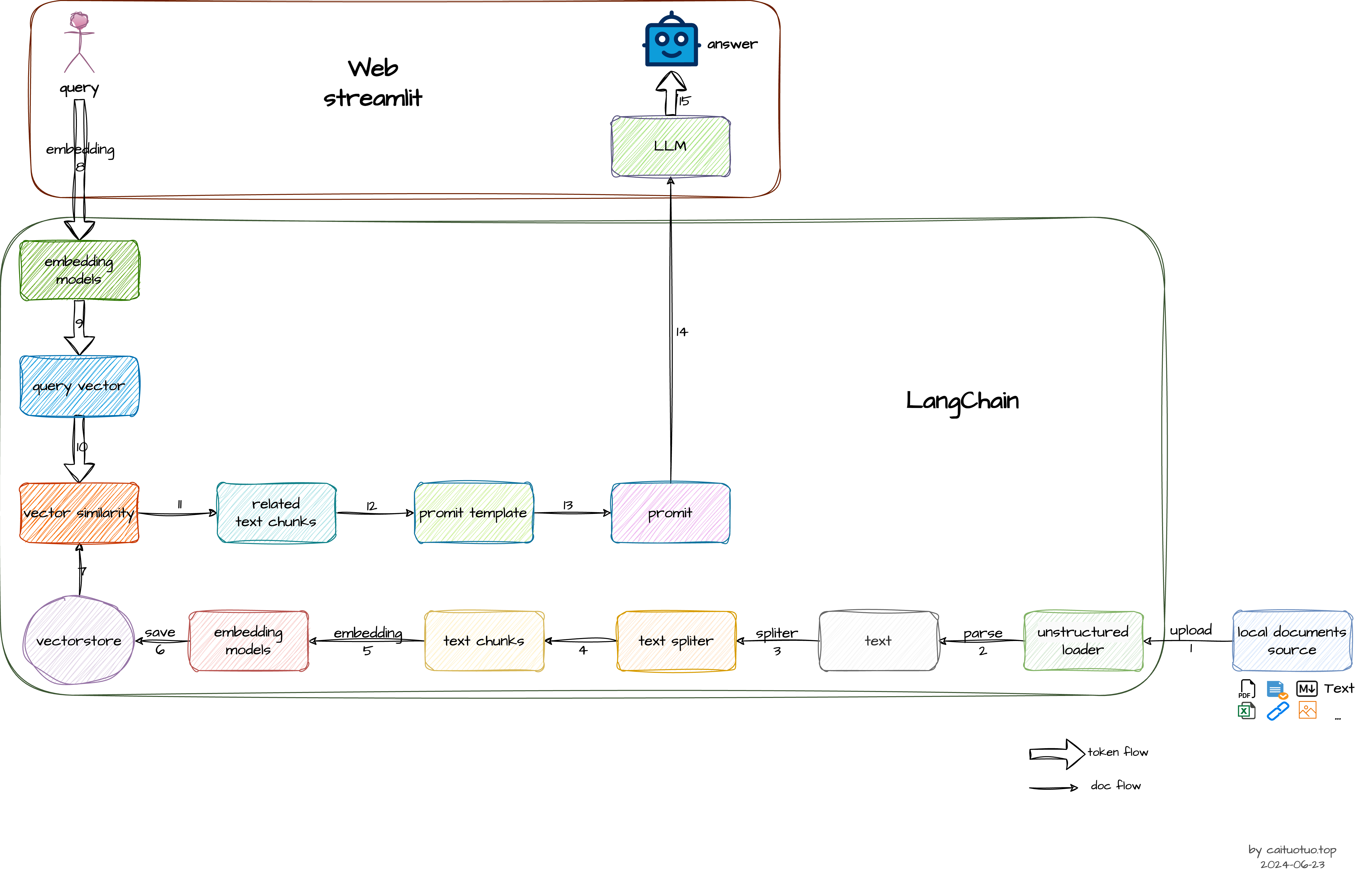
doc flow 文档处理流程
-
首先,
从本地加载文档(upload & loader),比如:pdf、txt、csv、md等从许多不同来源加载文档,LangChain提供了100多种不同的文档加载器。
-
加载完成后,对文档进行处理,
提取文档信息 -
提取完文档信息后,进行
文本切分-
为什么要切分文本?
因为有时候我们的文档内容比较多,比如一本书,这种情况下不可能一次性去处理,就需要将文本切成一块一块的,分块处理。
-
如何进行合理切分?
我们通常希望将主题相同的文本片段放在一块。例如,Markdown文件是由h1、h2、h3等多级标题组织的,我们可以根据Markdown标题分割文本内容,把标题相同的文本片段组织在一块。借助LangChain的MarkdownHeaderTextSplitter文本切割器实现。
-
-
文档切割后得到
文本块 -
对切割完成后的文本块进行
Embedding向量编号Embedding这里我们会用到很多模型,比如可以调用OpenAI的接口(收费),还可以用HuggingFaceHub(免费)等。
-
将所有文本的编码全部存储到
向量数据库中例如:Faiss、Pinecone、Chroma、Milvus等
token flow 用户提问&AI回答
- 用户进行
提问,输入一个问题 - 对用户输入的问题进行
Embedding编码 - 将用户输入的向量与数据库中所有的向量进行
相似性计算,即用户的提问跟数据库里哪些文本的相关性最高 文本召回,把达到某一个阈值的相关文本全部召回- 将召回的文本结合问题,形成一个
上下文的模板 - 基于上下文模板
向大模型LLM提问 - 获取到我们想要的
答案
优点
这种实现方式有什么好处呢?
- 我们可以让大语言模型在回答问题的时候是基于我们提供的文档范围去回答,减少AI幻觉,避免一本正经的胡说八道。
- 大语言模型可能信息更新不及时,基于我们提供的文档去回答,也解决了信息不及时的问题。