大模型的Token究竟是什么?

大模型的Token究竟是什么?
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/3be51b30.html

前言
你好,我是测试蔡坨坨。
上周,我们聊了「什么是模型参数?」
今天,我们接着来聊聊大模型的另一个关键词——Token。
你有没有遇到过这种情况:问 AI 一个很长的问题,它回答到一半突然中断?或者让它写代码时,代码最后几行“神秘消失”?
罪魁祸首很可能是一个叫Token的东西。
Token是什么?
人类的字 vs AI 的 Token
大语言模型的Token究竟是什么东西呢?它其实是大模型处理文本的最小单位,也是控制成本和效果的关键密码。
像DeepSeek、ChatGPT这样的大语言模型背后都有一个“剪刀手”爱德华,叫做分词器。当大模型接收到一段文字,会让分词器把它切成很多个小块,这切出来的每个小块就叫做一个Token。
比如这一段话「我们的心愿是世界和平!」在大模型里可能会被切成这个样子:

像「心」「愿」「是」这样单个的汉字可能是一个Token;两个汉字构成的词语「世界」「和平」也可能是一个Token;三个字构成的常见短语「我们的」也可能是一个Token;一个单词「Peace」「and」「Love」也可能是一个Token;一个标点符号「!」「.」也可能是一个Token ……
大模型在输出文字的时候也是一个Token一个Token的往外蹦,所以看起来有点像打字一样,也就是流式输出。
那么问题来了,为什么Token既可以是一个字,又可以是两个字,还可以是三个字,又可以是一个单词或者半个单词呢?这到底是怎么定义出来的。
举个简单的例子,当我们单独去看「旯」「妁」「圳」「侈」「邯」这些字的时候,可能没办法一眼看出是什么,但是当我们把这些字放到词语中「犄角旮旯」「媒妁之言」「深圳」「奢侈」「邯郸学步」的时候,你瞬间就可以念出来。
之所以会这样,是因为我们的大脑在日常生活中,喜欢把这些有含义的词语或短语,优先作为一个整体来对待,不到万不得已不会一个字一个字地去抠字眼,这就导致我们对这些词语还挺熟悉,单看这些字却有点陌生,而大脑之所以要这么做,是因为这样可以节省脑力,咱们的大脑还是非常懂偷懒的。
比如「人工智能」这四个字,如果一个字一个字的处理,一共需要有4个部分「人」「工」「智」「能」,但如果划分成2个常见且有意义的词语「人工」「智能」,就只需要处理两部分之间的关系,从而提高效率,节省脑力。
既然人脑可以这么做,那么人工智能当然也可以这么做,所以就有了分词器专门帮大模型把大段的文字拆解成大小合适的一个个Token,不同的分词器它的分词方法和结果当然不一样,分得越合理大模型就轻松。这就好比切工越好,做起菜来就越省事。
Token 的“切割规则”
那么分词器究竟是怎么分的词呢?不同模型的策略可能不同。
比如其中一个方法可能是,分词器统计了大量文字之后,发现「和平」这两个字经常一起出现,就把它们打包成一个Token,并给他一个数字编号188791,然后丢到一个大的词汇表里,这样下次再看到「和平」这两个字,直接认出这个组合就可以了。
然后它可能又发现「心」这个字经常出现,并且可以搭配不同的其他字,于是它就把「心」这个字打包成一个Token,配一个编号8477并且丢到词汇表里。
它又发现「我们的」这三个字经常一起出现,于是又把「我们的」打包成一个Token,配一个编号155930,收录到表里去。
它又发现「!」经常出现,于是把「!」也作为一个Token,给它一个编号3393,输入到表里去。

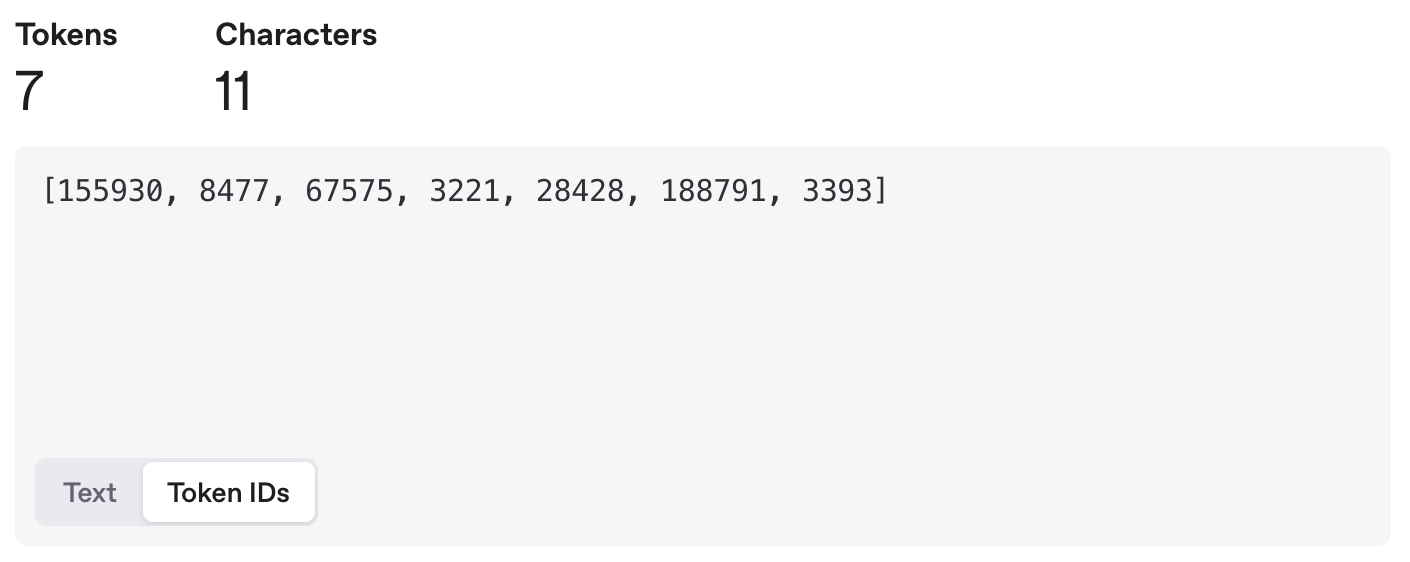
经过大量统计和收集,分词器就可以得到一个庞大的Token表,可能有五万个、十万个,甚至更多Token。可以囊括我们日常见到的各种字、词、符号等等。
这样一来,大模型在输入和输出的时候,都只需要面对一堆数字编号就可以了,再由分词器按照Token表转换成人类可以看懂的文字和符号。这样一分工,工作效率就非常高。
-
英文:常用子词(subword)拆分,解决长尾词汇问题
例如:“unbelievable” → [“un”, “belie”, “vable”]
-
中文:按词或字拆分(不同模型策略不同)
例如:“人工智能” → [“人工”, “智能”] 或 [“人”, “工”, “智”, “能”]
PS:Token ≠ 单词!它是模型词典中的独立片段,类似乐高积木的基础模块。
我们可以使用Token计算器(https://tiktokenizer.vercel.app),输入一段话,选择模型,它就可以告诉你这段话是由几个Token构成,分别是什么,以及这几个Token的编号分别是什么:
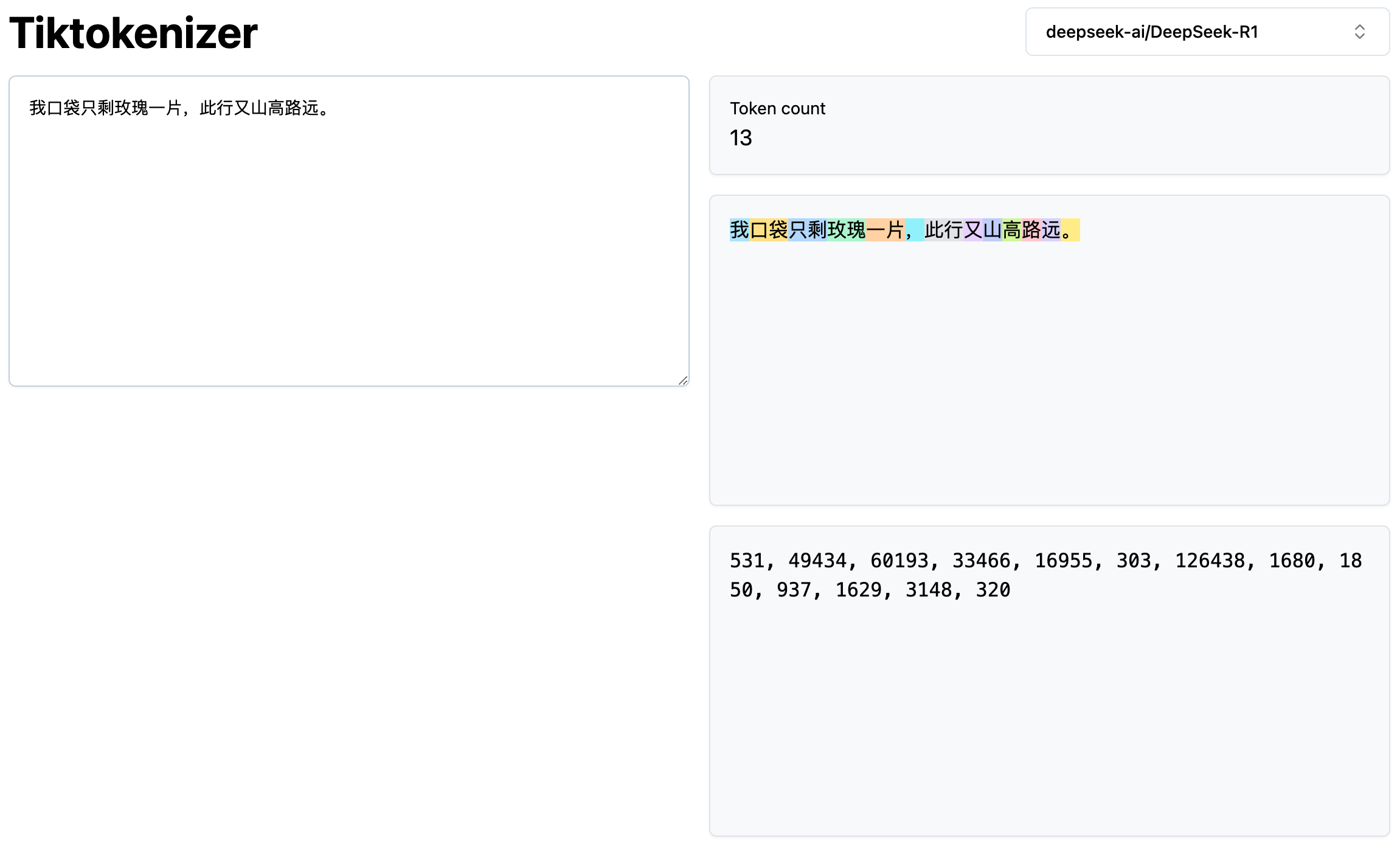
所以回过头来看,Token到底是什么?Token就是大模型世界里的一块块积木,大模型之所以可以理解和生成文字,就是靠计算这些Token之间的关系来推算出下一个Token最有可能是哪一个。这也是为什么几乎所有大模型公司都是按照Token的数量来计费,因为Token的数量对应了背后的计算量。
单个 Token 就像一只蚂蚁,看似微不足道;但当万亿级 Token 像蚁群般协同工作时,它们便构建起了大模型的“巴别塔”。


