彻底学会Selenium元素定位

彻底学会Selenium元素定位
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/63099961.html
你好,我是测试蔡坨坨。
最近收到不少初学UI自动化测试的小伙伴私信,对于元素的定位还是有些头疼,总是定位不到元素,以及不知道用哪种定位方式更好。
其实UI自动化测试的本质就是将手工测试的一系列动作转化成机器自动执行,可以简单概括为五大步骤:定位元素 - 操作元素 - 模拟页面动作 - 断言结果 - 生成报告。所以很多同学在学习时,都是以元素定位作为入门导向,好的开始就是成功的一半。因此,本篇将详细介绍Selenium八大元素定位方法,以及在自动化测试框架中如何对元素定位方法进行二次封装,最后会给出一些在定位元素时的经验总结。
注意:本文出现的代码示例均以 Python3.10 + Selenium4.5.0 为准,由于网上大多数教程都是Selenium3,Selenium4相比于Selenium3会有一些新的语法,如果你还不了解Selenium4,推荐先阅读往期文章「Selenium 4 有哪些不一样?」。
Selenium八大元素定位
所谓八大元素定位方式就是id、name、class_name、tag_name、link_text、partial_link_text、xpath、css_selector。
在介绍定位方式之前先来说一下定位工具,以Chrome浏览器为例,使用F12或右键检查进入开发者工具。
ID
通过元素的id属性定位,一般情况下id在当前页面中是唯一的。使用id选择器的前提条件是元素必须要有id属性。由于id值一般是唯一的,因此当元素存在id属性值时,优先使用id方式定位元素。
例如:下面的这个input标签的id属性值为kw
1 | <input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off"> |
语法:
1 | driver.find_element(By.ID, "id属性值") |
举栗:
1 | # author: 测试蔡坨坨 |
NAME
通过元素的name属性来定位。name定位方式使用的前提条件是元素必须有name属性。由于元素的name属性值可能存在重复,所以必须确定其能够代表目标元素唯一性后,方可使用。
当页面内有多个元素的特征值相同时,定位元素的方法执行时只会默认获取第一个符合要求的特征对应的元素。
例如:下面的这个input标签的name属性值为wd
1 | <input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off"> |
语法:
1 | driver.find_element(By.NAME, "name属性值") |
举栗:
1 | # author: 测试蔡坨坨 |
CLASS_NAME
通过元素的class属性来定位,class属性一般为多个值。使用class定位方式的前提条件是元素必须要有class属性。
虽然方法名是class_name,但是我们要找的是class属性。
例如:下面这个input标签的class属性值为but1
1 | <input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字" value=""> |
语法:
1 | driver.find_element(By.CLASS_NAME, "class属性值") |
举栗:
1 | # author: 测试蔡坨坨 |
注意:如果class name是一个复合类(存在多个属性值,每个属性值以空格隔开),则只能使用其中的任意一个属性值进行定位,但是不建议这么做,因为可能会定位到多个元素。
例如:下面这个标签的class属性值为bg s_btn btn_h btnhover
1 | <input class="bg s_btn btn_h btnhover" type="text" name="key"> |
则只能使用复合类的任意一个单词去定位:
1 | driver.find_element(By.CLASS_NAME,"bg") # 正确示范 |
TAG_NAME
通过元素的标签名称来定位,例如input标签、button标签、a标签等。
由于存在大量标签,并且重复性高,因此必须确定其能够代表目标元素唯一性后,方可使用。如果页面中存在多个相同标签,默认返回第一个标签元素。一般情况下标签重复性过高,要精确定位,都不会选择tag_name定位方式。
语法:
1 | driver.find_element(By.TAG_NAME, "标签名称") |
举栗:
1 | driver.find_element(By.TAG_NAME, "input") |
LINK_TEXT
定位超链接标签。只能使用精准匹配(即a标签的全部文本内容),该方法只针对超链接元素(a 标签),并且需要输入超链接的全部文本信息。
例如:下面这个a标签的全部文本内容为联系客服
1 | <a href="http://XXX">联系客服</a> |
语法:
1 | driver.find_element(By.LINK_TEXT, "a标签的全部文本内容") |
举栗:
1 | # author: 测试蔡坨坨 |
PARTIAL_LINK_TEXT
定位超链接标签,与LINK_TEXT不同的是它可以使用精准或模糊匹配,也就是a标签的部分文本内容,如果使用模糊匹配最好使用能代表唯一的关键词,如果有多个元素,默认返回第一个。
例如:下面这个a标签的全部文本内容为“联系客服”,模糊匹配就可以使用a标签的部分文本内容,比如联系、客服、联、服……
1 | <a href="http://XXX">联系客服</a> |
语法:
1 | driver.find_element(By.PARTIAL_LINK_TEXT, "a标签的部分文本内容") |
举栗:
1 | # author: 测试蔡坨坨 |
XPATH
定义
XML Path Language 的简称,用于解析XML和HTML。(不仅可以解析XML还可以解析HTML,因为HTML与XML是非常相像的,XML多用于传输和存储数据,侧重于数据,HTML多用于显示数据并关注数据的外观)
Xpath策略有多种,无论使用哪一种策略,定位的方法都是同一个,不同策略只决定方法的参数的写法。
Xpath不仅可以用于Selenium,还适用于Appium,是一个万能的定位方式。
Xpath有一个缺点,就是速度比较慢,比CSS_SELECT要慢很多,因为Xpath是从头到尾一点一点去遍历。
绝对路径
从最外层元素到指定元素之间所有经过元素层级的路径 ,绝对路径是以/html根节点开始,使用 / 来分割元素层级的语法,比如:/html/body/div[2]/div/div[2]/div[1]/form/input[1](因为会有多个div标签,所以用索引的方式定位div[2],且XPath的下标是从1开始的,例如:/bookstore/bool[1]表示选取属于bookstore子元素的第一个book元素,除了用数字索引外,还可以用last()、position()函数来表达索引,例如:/bookstore/book[last()]表示选取属于bookstore子元素的最后一个book元素,/bookstore/book[last()-1]表示选取属于bookstore子元素的倒数第二个book元素,/bookstore/book[position()<3]表示选取最前面的两个属于bookstore元素的子元素的book元素)
由于绝对路径对页面结构要求比较严格,因此不建议使用绝对路径。
语法:
1 | driver.find_element(By.XPATH, "/html开头的绝对路径") |
举栗:
1 | # author: 测试蔡坨坨 |
相对路径
匹配任意层级的元素,不限制元素的位置 ,相对路径是以 // 开始, // 后面跟元素名称,不知元素名称时可以使用 * 号代替,在实际应用中推荐使用相对路径。
语法:
1 | driver.find_element(By.XPATH, "//input") |
举栗:
1 | # author: 测试蔡坨坨 |
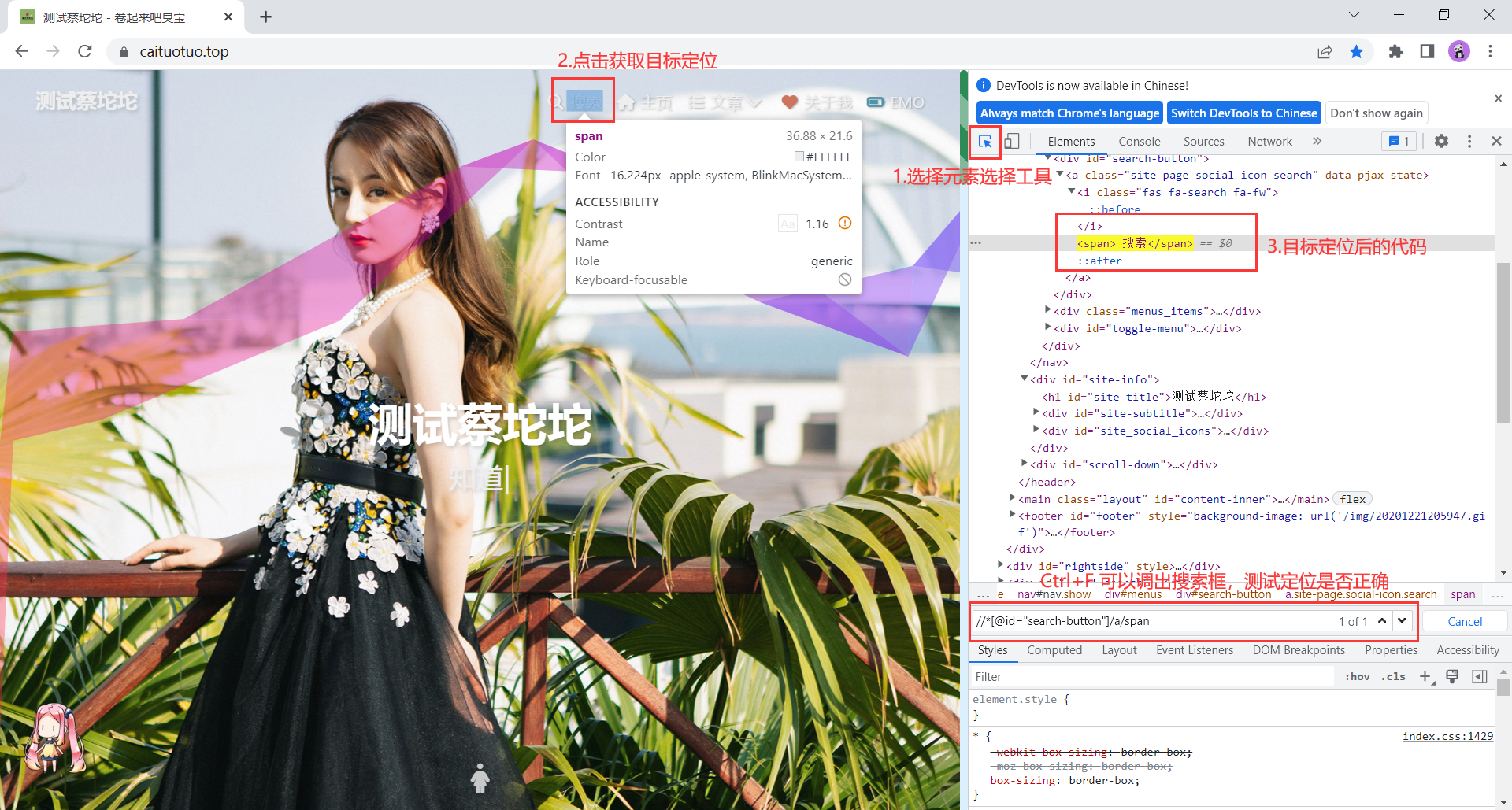
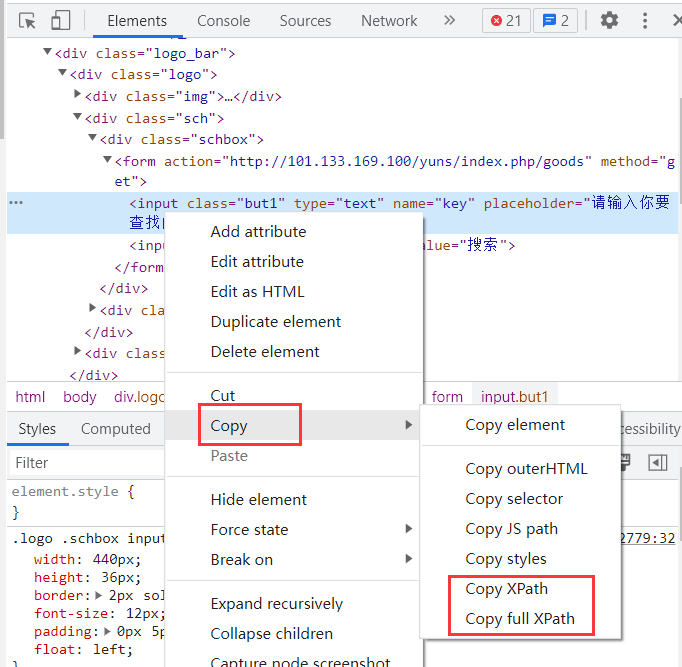
使用浏览器开发者工具直接复制xpath路径值(偷懒的方法,不推荐在学习的时候使用):
通过元素属性定位
单个属性
使用目标元素的任意一个属性和属性值(需保证唯一性)。
注意:
使用 XPath 策略,建议先在浏览器开发者工具中根据策略语法,组装策略值,测试验证后再放入代码中使用。
目标元素的有些属性和属性值可能存在多个相同特征的元素,需注意唯一性。
语法:
1 | driver.find_element(By.XPATH, "//标签名[@属性='属性值']") |
比如:下面这个input标签的placeholder属性的属性值为“请输入你要查找的关键字”
1 | <input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字"> |
举栗:
1 | # author: 测试蔡坨坨 |
多个属性
通过多个属性和属性值进行匹配,解决单个属性和属性值无法定位元素唯一性的问题。
多个属性可由多个 and 连接,每一个属性都要以 @ 开头,可以根据需求使用更多属性值。
语法:
1 | driver.find_element(By.XPATH, "//标签名[@属性1='属性值1' and @属性2='属性值2']") |
比如:下面这个input标签的class属性的属性值为”but1”,placeholder属性的属性值为”请输入你要查找的关键字”
1 | <input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字" value=""> |
举栗:
1 | # author: 测试蔡坨坨 |
通过属性模糊匹配
通过属性值的部分内容进行匹配。
语法:
1 | driver.find_element(By.XPATH, "//标签名[contains(@属性,'属性值的部分内容')]") |
比如:下面这个input标签的placeholder属性的属性值为”请输入你要查找的关键字”,模糊匹配就可以是”请输入”
1 | <input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字"> |
举栗:
1 | # author: 测试蔡坨坨 |
starts-with属性值以XX开头
语法:
1 | driver.find_element(By.XPATH, "//标签名[starts-with(@属性,'属性值的开头部分')]") |
比如:下面这个input标签的placeholder属性的属性值以”请输入”开头
1 | <input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字"> |
举栗:
1 | # author: 测试蔡坨坨 |
文本值定位
通过标签的文本值进行定位,定位文本值等于XX的元素,一般适用于p标签、a标签。
语法:
1 | driver.find_element(By.XPATH, "//*[text()='文本信息']") |
比如:下面这个a标签的文本信息为”免费注册”
1 | <a href="http://127.0.0.1/register">免费注册</a> |
举栗:
1 | # author: 测试蔡坨坨 |
CSS_SELECTOR
通过CSS选择器语法定位元素。
适用于Selenium和Appium,但是需要注意的是,原生的app控件不支持CSS_SELECTOR,只支持Xpath。
Selenium框架官方推荐使用CSS定位,因为CSS定位效率高于XPATH。
CSS是一种标记语言,控制元素的显示样式,就必须找到元素,在CSS标记语言中找元素使用CSS选择器。
CSS的选择策略也多很多种,但是无论选择哪一种选择策略都是用同一种定位方法。
定位方法:
1 | driver.find_element(By.CSS_SELECTOR, "CSS选择策略") |
绝对路径
以html开始,使用 > 或 空格 分隔,与XPATH一样,CSS_SELECTOR的下标也是从1开始。
1 | driver.find_element(By.CSS_SELECTOR, "html>body>div>div>div>div>form>input:nth-child(1)").send_keys("测试蔡坨坨") # 使用>分隔 |
相对路径
不以html开头,以CSS选择器开头,比如标id选择器、class选择器等。
举栗:
1 | driver.find_element(By.CSS_SELECTOR, "input.but1").send_keys("测试蔡坨坨") |
id选择器
语法:# 开头表示id选择器
1 | driver.find_element(By.CSS_SELECTOR, "标签#id属性值") |
举栗:
1 | driver.find_element(By.CSS_SELECTOR, "i#cart_num").click() |
class选择器
语法:. 开头表示class选择器,或者使用[class=’class属性值’]
如果具有多个属性值的class,则需要传入全部的属性值
1 | driver.find_element(By.CSS_SELECTOR, ".class属性值") |
举栗:
1 | driver.find_element(By.CSS_SELECTOR, ".but2").click() |
属性选择器
单个属性
语法:
1 | driver.find_element(By.CSS_SELECTOR, "标签名[属性='属性值']") |
举栗:
1 | driver.find_element(By.CSS_SELECTOR, "input[placeholder='请输入你要查找的关键字']").send_keys("测试蔡坨坨") |
多个属性
语法:注意与xpath的区别
1 | driver.find_element(By.CSS_SELECTOR, "标签名[属性1='属性值1'][属性2='属性值2']") |
举栗:
1 | driver.find_element(By.CSS_SELECTOR, "input[name='key'][class='but1']").send_keys("测试蔡坨坨") |
模糊匹配
1 | driver.find_element(By.CSS_SELECTOR, "[属性^='开头的字母']") # 获取指定属性以指定字母开头的元素 |
标签选择器
语法:
1 | driver.find_element(By.CSS_SELECTOR, "标签名") # 例如:input、button |
层级关系
父子层级关系:父层级策略 > 子层级策略 (也可以使用空格连接上下层级)
祖辈后代层级关系:祖辈策略 后代策略
> 与 空格 的区别:大于号必须为子元素,空格则不用
first-child
第一个子元素
1 | <div class="help"> |
1 | driver.find_element(By.CSS_SELECTOR, ".help>a:first-child").click() # 首页 |
last-child
最后一个子元素
1 | driver.find_element(By.CSS_SELECTOR, ".help>a:last-child").click() # 联系客服 |
nth-last-child()
倒序
1 | driver.find_element(By.CSS_SELECTOR, ".help>a:nth-last-child(2)").click() # 我的订单 |
nth-child()
正序
1 | driver.find_element(By.CSS_SELECTOR, ".help>a:nth-child(3)").click() # 联系客服 |
干儿子和亲儿子
若一个标签下有多个同级标签,虽然这些同级标签的 tag name 不一样,但是他们是放在一起排序的。
1 | # author: 测试蔡坨坨 |
元素定位二次封装
在之前的文章中我们介绍过UI自动化测试框架,可参考往期文章「五分钟搞懂 POM 设计模式」。
框架中的base_page模块对Selenium一些常用的API进行二次封装,其中就有对find_element的封装。
base_page.py:
1 | class BasePage(object): |
元素定位总结
首先考虑id定位,id定位是效率最高的
一般情况下id属性在当前页面是唯一的。
在实际企业项目中,可能需要前端同学的配合,保证元素唯一属性命名规则。所有可操作元素,例如输入框、点击按钮等均需要加id字段,并且id字段的命名为元素含义的英文;若当前页面存在两个或多个一样的元素,则第二个开始命名为id=username2,以此类推;多层级元素一般最外层定义即可。
如果没有id,再选择xpath,一般使用相对路径
css_selector比xpath更加稳定
为什么说css_selector比xpath更稳定?因为我们通过Chrome浏览器的开发者工具可以看出蓝色线代表DOM出现,红色线代表图片等资源已加载完,如果用xpath定位元素,其实是在DOM出现的时候进行查找,而当你使用css_selector进行元素定位的时候,它会等待图片资源加载完成后进行查找,也就是红线的位置,所以css_selector比xpath更稳定,当你使用xpath定位不到元素时,不妨尝试使用css_selector。

tag_name使用频率最低
尽量不要用href属性、纯数字的属性(纯数字可能是个动态值)去定位
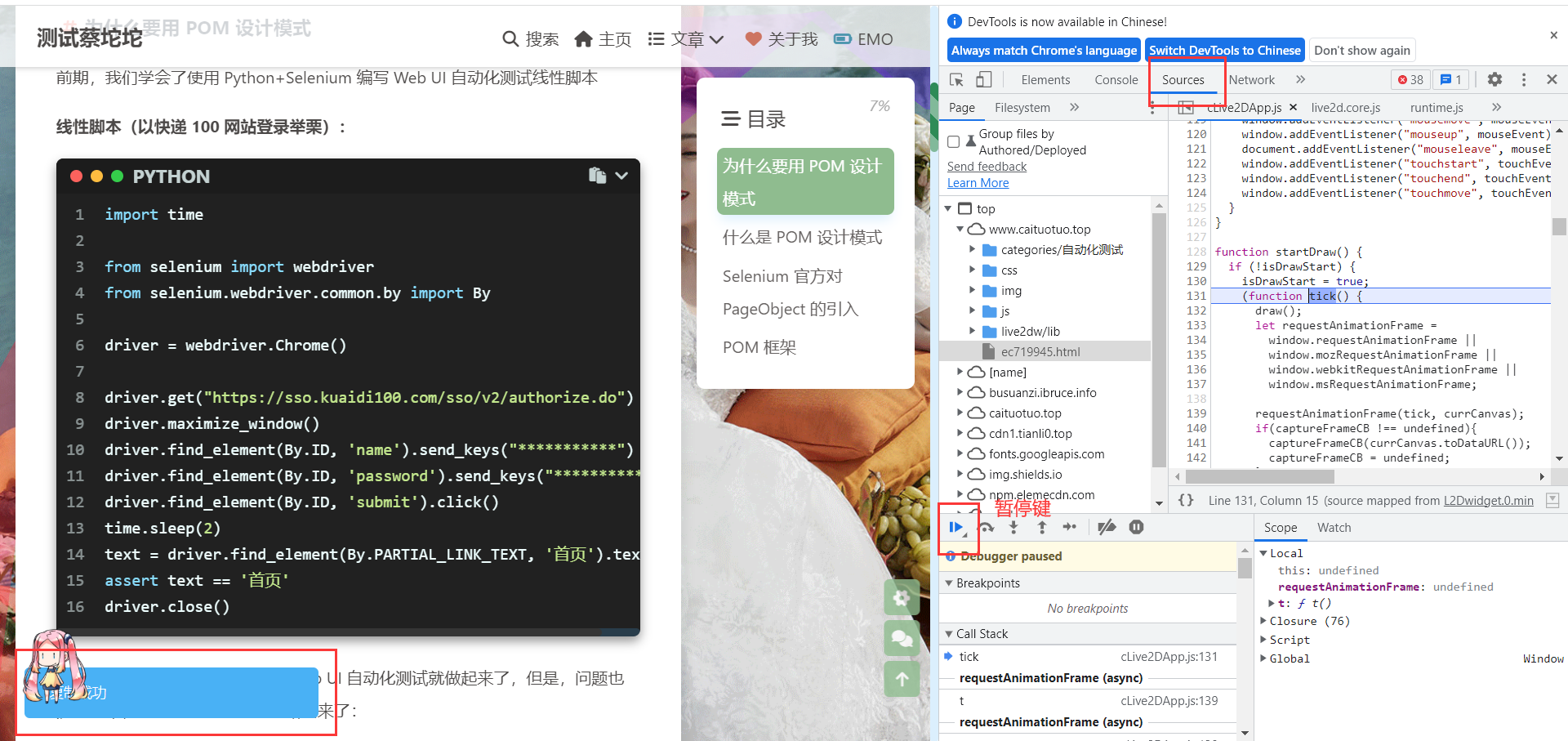
对于Toast提示框,很快消失的提示框,可以点击 开发者工具-sources中的暂停键 后再去定位
添加适当的等待时间,避免等待时间不够,元素还未加载出来
多窗口时需考虑窗口句柄是否还处在上一个窗口,导致无法定位新窗口的元素,是否需要切换窗口句柄
iframe/frame,这是个常见的定位不到元素的原因,frame中实际上是嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此需要先定位到相应的frame,再对那个页面里的元素进行定位
如果使用xpath或css_selector,请在浏览器开发者工具中调试测试正确后再写入代码中