Ollama 0.4发布!支持Llama 3.2 Vision,实现多模态RAG

Ollama 0.4发布!支持Llama 3.2 Vision,实现多模态RAG
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/603bb2e6.html
前言
你好,我是测试蔡坨坨。
最近,Ollama 推出了 0.4 版本,其中最大的亮点就是支持了 Llama 3.2 Vision 模型,该模型具备多模态特性,也就是说能够理解图像并将图像纳入提示词中进行处理,让模型更智能地处理RAG中的数据源,实现强大的视觉处理功能,例如:手写识别,准确读取手写内容;OCR识别,识别订单、账单等文档;图表与表格识别,解析各类数据;图像问答,实现图片内容的问答交互。
这种功能在之前的Ollama版本中是不支持的,因为Llama CPP不支持视觉模型。
在本篇文章中,我们就来体验一下这个“多模态”神器。
模型下载&运行

目前 Ollama 支持 11B 和 90B 的 Llama 3.2 Vision 模型,使用方式也很简单,使用 ollama pull/run 就能下载并运行模型:
1 | ollama run llama3.2-vision |
运行较大的 90B Llama 3.2 Vision 模型:
1 | ollama run llama3.2-vision:90b |
视觉能力测试
我们在终端运行Llama 3.2 Vision模型,并使用一些图像来测试大模型的视觉能力。
1. 识别物体
首先来个最简单的,让大模型回答图片中包含哪些物品。
测试图片:

运行方式也比较简单,先输入你要提问的文本内容,再将图片路径给到大模型:
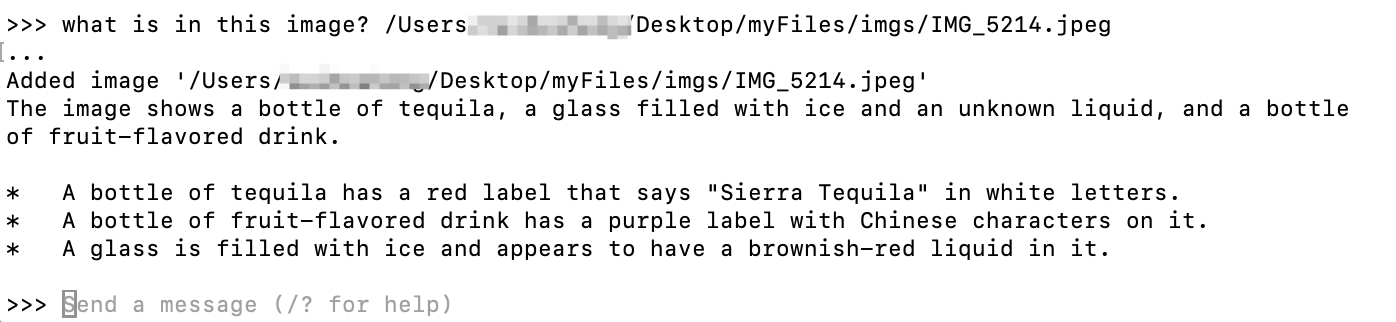
回答的效果看起来还是不错的,包含了图片的基本元素,一瓶龙舌兰、装满冰块的杯子以及一瓶果汁,而且还对这些元素做了详细分析,包括颜色(red label、white letters、purple label)、文字(Sierra Tequila、Chinese charaters)等。
当然了,整个图片比较简单,对比度也比较强,比较清晰,所以大模型还是比较好识别的。
2. 流程图分析
加大难度,让模型识别流程图并描述出每一步骤。
测试图片:
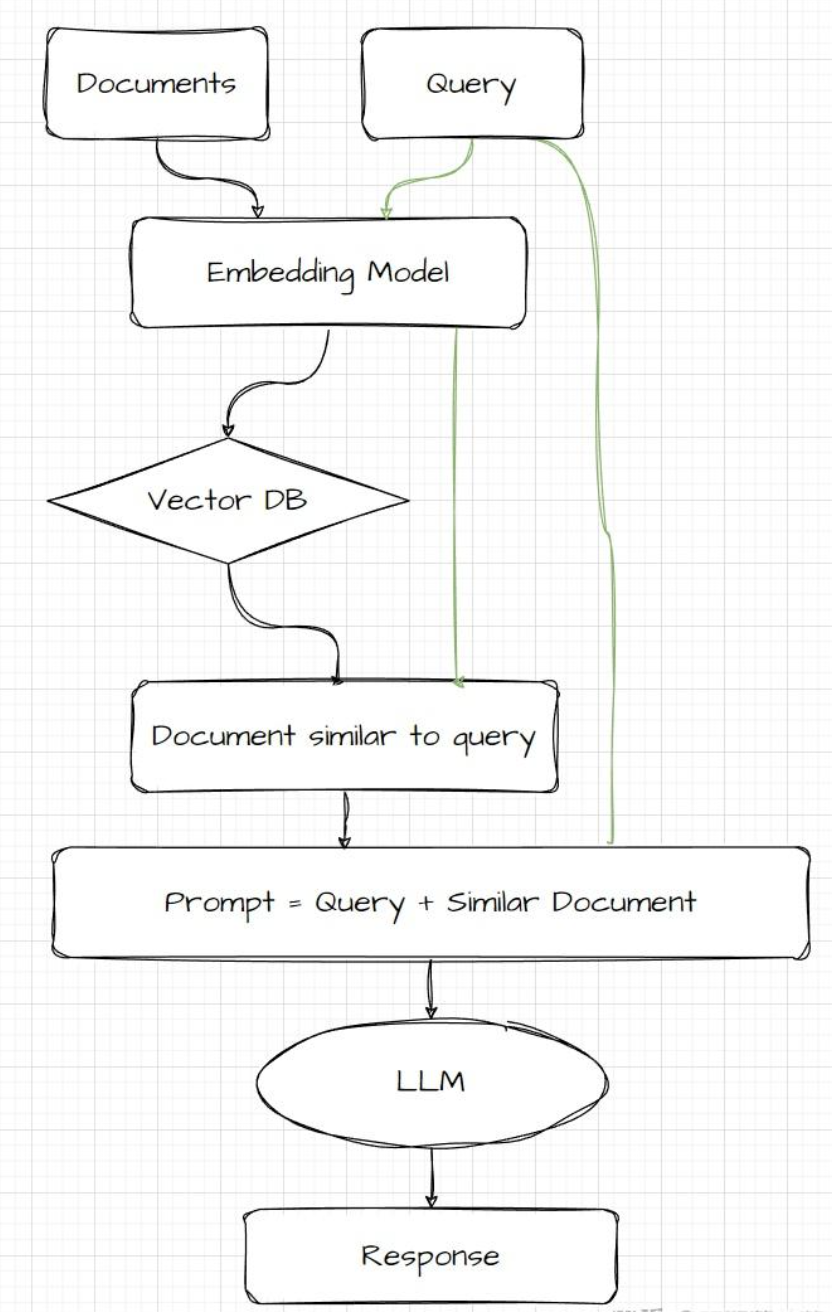
将流程图给到大模型,并让它拆解流程图中的每个步骤:

回答效果也还行,每个步骤也都很详细(很大原因是因为流程图使用的是英文,中文的话就一言难尽了)。
3. 图片数据分析
再加大难度,让模型识别图片中的数据信息,并进行分析和总结,图片内容包含数字、中文、统计图等信息。
测试图片:
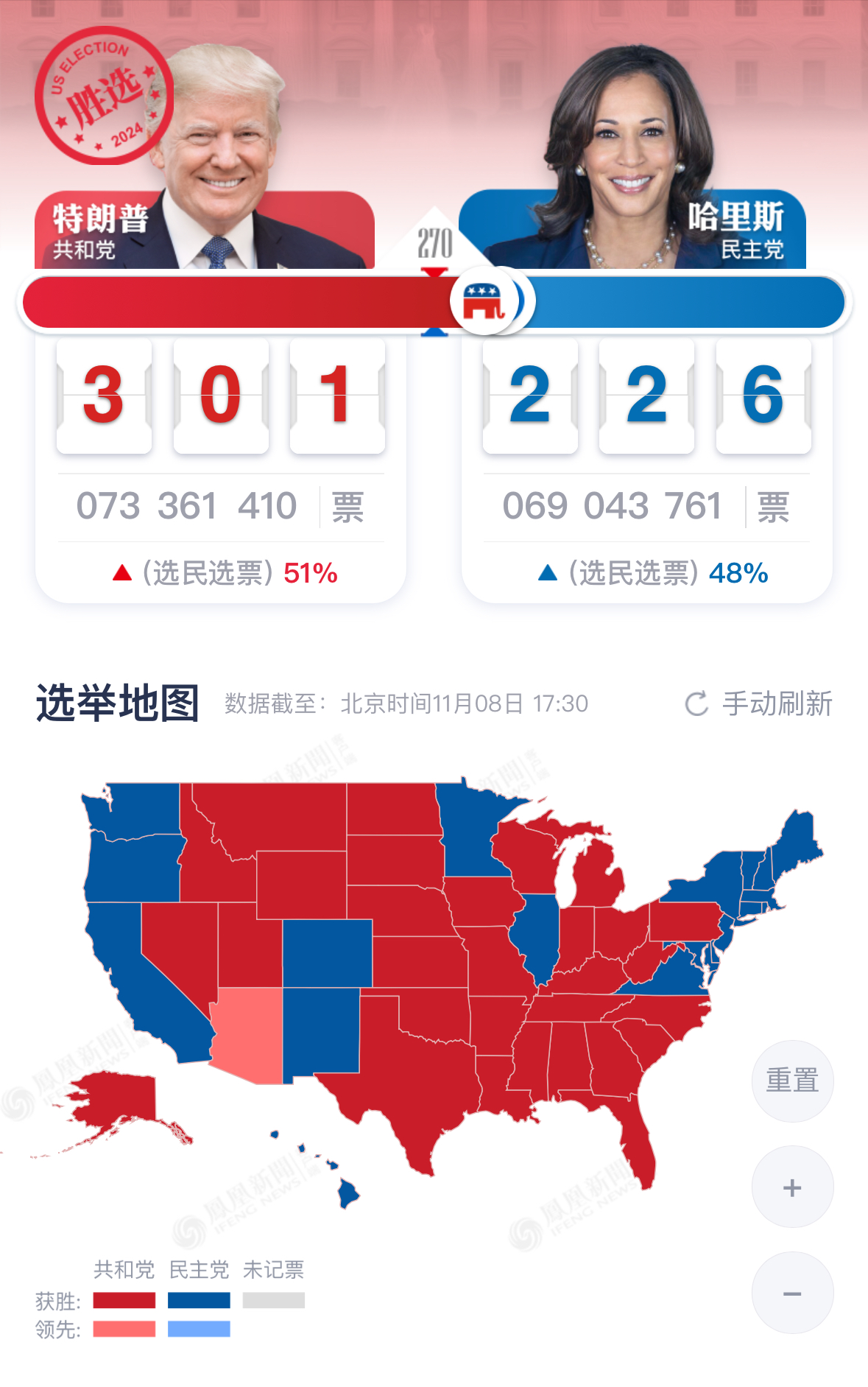
让大模型对图片内容进行分析,并在提示词中输入关键数字301和226:
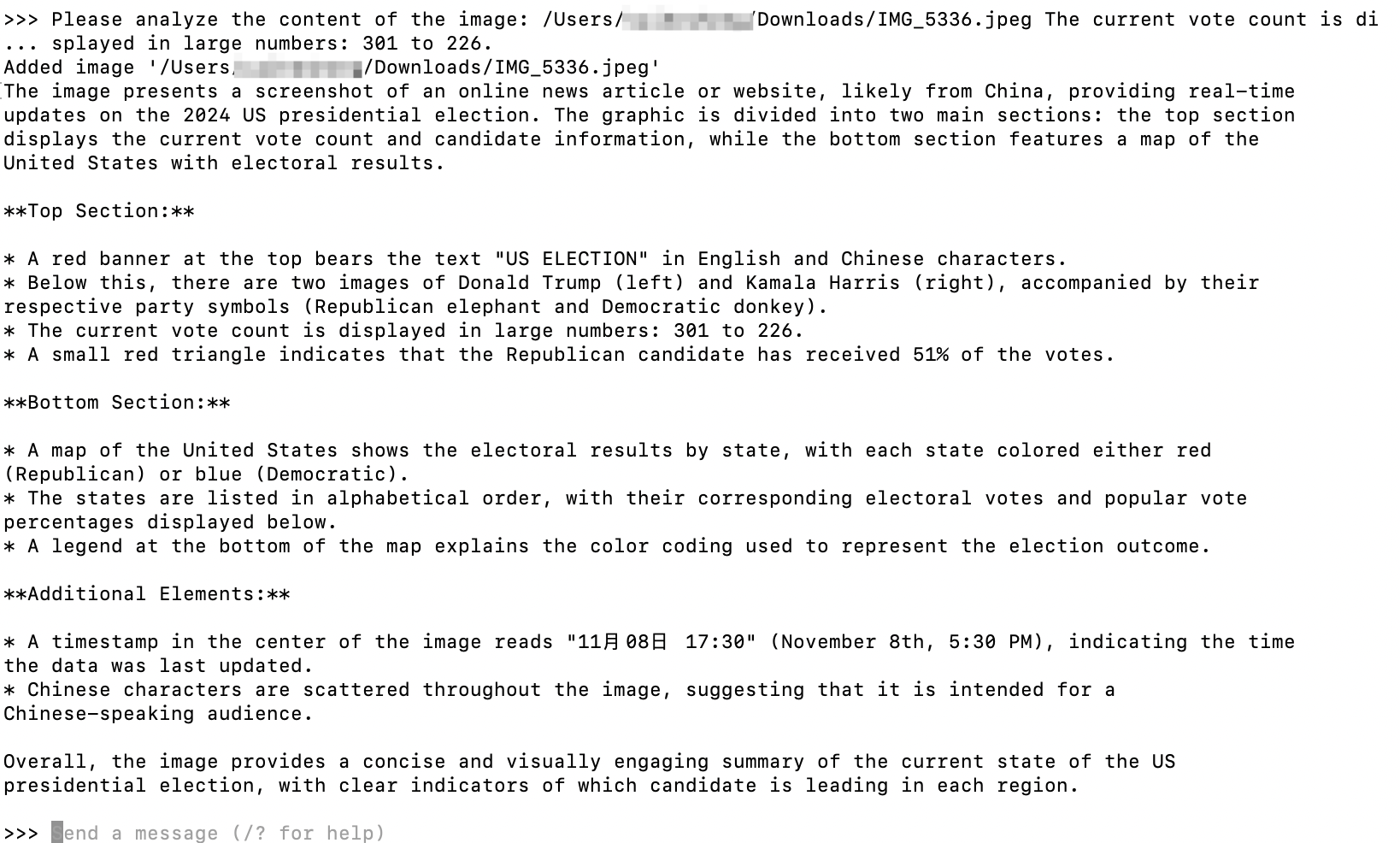
这段Llama 3.2 Vision模型生成的回答还是比较详尽且有条理的,值得我们对回答结果做进一步分析:
信息提取的准确性
首先,模型相对准确地提取了图像中的关键信息,包括
图片来源(The image presents a screenshot of an online news article or website, likely from China, providing real-time 可能来自中国的在线新闻文章或网站的截图)、候选人(Donald Trump (left) and Kamala Harris (right) 特朗普和哈里斯)、当前的得票情况(The current vote count is displayed in large numbers: 301 to 226、A small red triangle indicates that the Republican candidate has received 51% of the votes 票数和比例)、各州选举结果地图(A map of the United States shows the electoral results by state, with each state colored either red (Republican) or blue (Democratic))等。层次分明的结构
回答将图片分为
顶部(Top Section)、底部(Bottom Section)和附加元素(Additional Elements)三个部分描述,每部分重点突出。这种结构使内容条理清晰,便于读者快速理解每个部分的关键内容。适当的细节呈现
模型描述了图片中的细节,比如
候选人党派标识(Republican elephant and Democratic donkey 共和党的大象和民主党的驴)、地图的配色说明(red (Republican) or blue (Democratic))、更新时间(”11月08日 17:30” (November 8th, 5:30 PM))等。这些细节增强了内容的完整性和丰富性,更全面地还原了图像中的内容。双语信息的兼容
尽管大模型对中文的理解有时令人一言难尽,但是在此示例中模型的回答指出了图片里中英文的存在,并且可以看出对简单中文的理解还是可以的。
在测试过程中,还是能发现一些不足之处。例如,为了保证模型识别正确,我在提示词中加上了关键数字“301”和“226”,因为在没有这个提示词之前,模型错误地将数字识别成“3001”和“2266”。
此外,模型的回答内容略显冗长。虽然它覆盖了丰富的信息,但有时过于详尽,难以让用户一眼抓住重点。简化和精炼是提升可读性的重要一步,我们可以引导模型聚焦于关键信息。
在背景信息方面,虽然模型识别了候选人得票情况,但并未提及候选人个人信息或背景,这对某些用户可能是重要信息。为此,适当补充更丰富的数据源能够帮助模型更全面地回答问题。
而在语言风格上,我们希望模型能“去AI化”,通过提示词引导它使用更具情感和幽默的表达方式,使文本读起来更自然、亲切。这样的调整尤其适合面向普通读者的内容,增强用户的阅读体验。
最后是中文支持方面,目前看来,Llama 的中文理解和表达还有提升空间。
大模型处理的速度和准确性跟图片本身的大小和分辨率也有很大的关系,并且以上三个栗子都是用的 Lllama 3.2 Vision 11B 模型测试,90B的模型效果应该更加优秀,感兴趣的小伙伴可以自己去尝试一下。
总而言之,Llama 3.2 Vision 为本地图像处理带来革命性突破,在未来也能够让 AI 视觉应用更智能、更高效。