通俗易懂地讲明白什么是模型参数?为什么本地部署的大模型笨笨的?

通俗易懂地讲明白什么是模型参数?为什么本地部署的大模型笨笨的?
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/ab320807.html

前言
你好,我是测试蔡坨坨。
在往期文章「DeepSeek的N种打开方式,别再被傻傻的割韭菜了!!!」中,我们盘点了DeepSeek的多种使用方式。
除了官网和API外,本地部署也是一种选择,特别是那些对数据安全有高要求、需要避免某些限制或追求高量而不求高质的场景。不过,由于我们大多数人的电脑配置有限,本地部署的模型通常是其他架构的蒸馏模型,参数一般都在32B/70B以下,而满血版的DeepSeek R1拥有671B的参数。
这个参数差距正是导致本地部署模型表现笨笨的根本原因。(实测表明,在 RAG 流程中,即使检索到相同的上下文并喂给大模型,不同模型的差异仍会影响最终答案的准确性。)
因此,本篇我们就来聊一聊大模型参数究竟是什么东西。
大模型参数是什么
参数参数,参天大树,参数参数,它其实就是一堆数字,是模型在训练过程中学到的数值。
例如:一个参数可能是 -12138.123,另一个可能是 3.1415926。像 DeepSeek R1 模型的最大版本是 671B,其中的 “B” 代表 Billion(10亿),也就是说,它拥有6710亿个类似这样的数。
你可以想象一张巨大的表格,每个格子里都有一个类似这样的数字,整个表格有几千亿个格子,而这些参数通常占据大模型 90% 以上的体积。大模型的 大 也就是体现在参数数量极多,这些参数共同构成了一个复杂的“知识网络”,让模型能处理复杂任务。
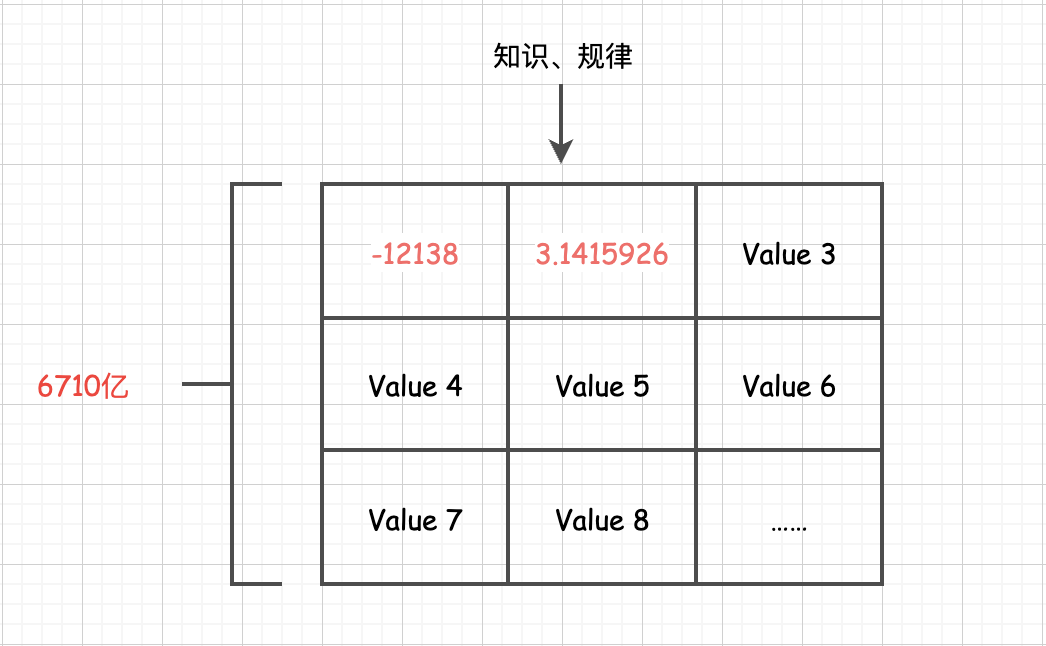
那么问题来了,为什么这些看似普通的数字构成的大模型,能蕴含如此丰富的知识和规律,甚至能够回答各种问题呢?
这就像初中数学中的一元一次函数 y = ax + b ,它可以用来拟合一条直线。只要你知道了这条直线 a 和 b 的值,你就掌握了这条线的所有点的分布规律,给你任何一个x坐标,你就可以快速推算出对应的y坐标。
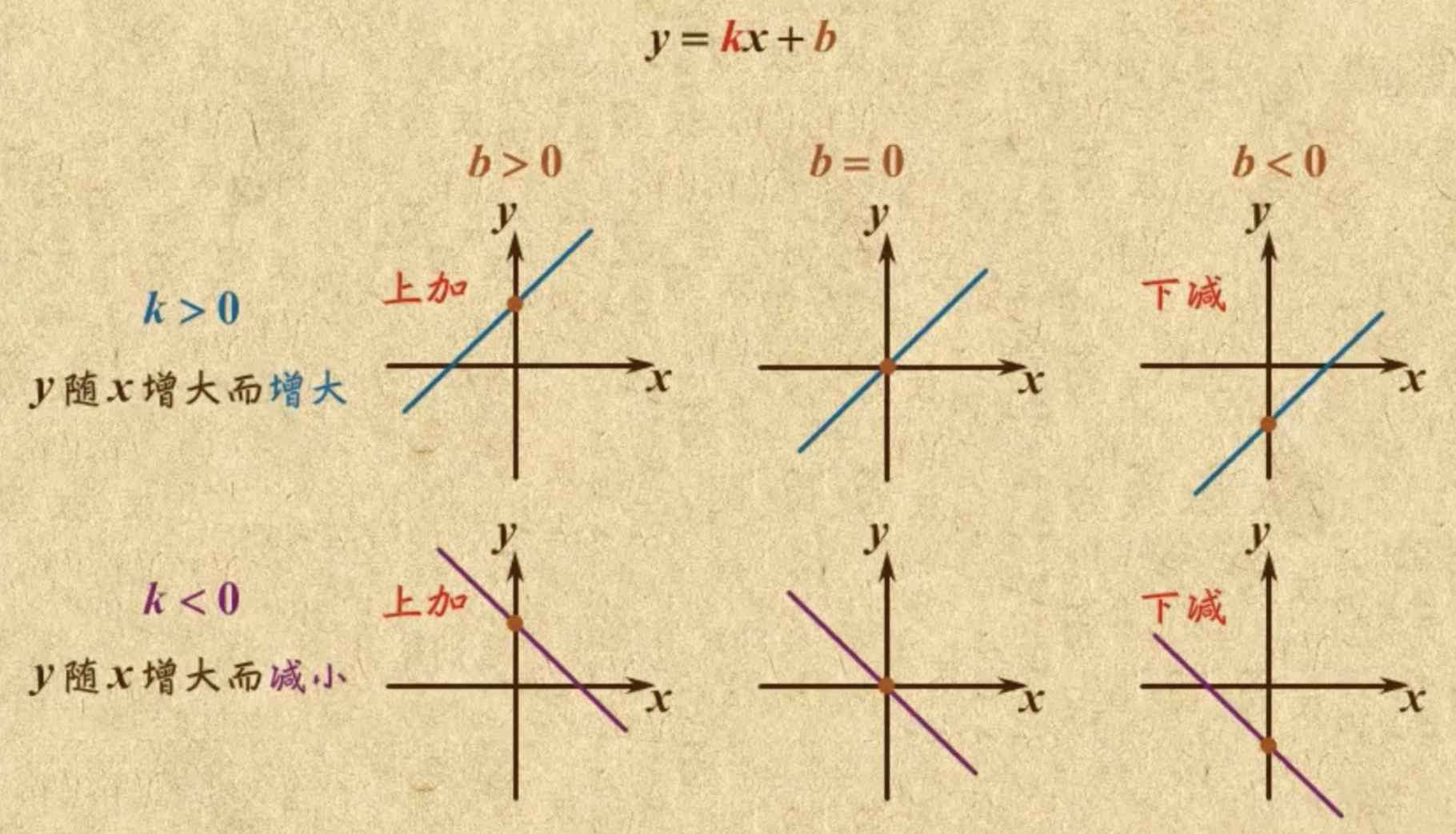
换句话说,一旦找到了合适的拟合方法,整条线上的无数点的分布规律就能被压缩成 a 和 b 这两个小小的参数。
规律可以被压缩到参数中,而大模型的工作就是将文字、图像或声音等世界中的各种分布规律压缩到一堆参数里。
只是,由于一条直线的分布规律相对简单,拟合它所需的方法和公式也比较简单,参数自然也就非常少。
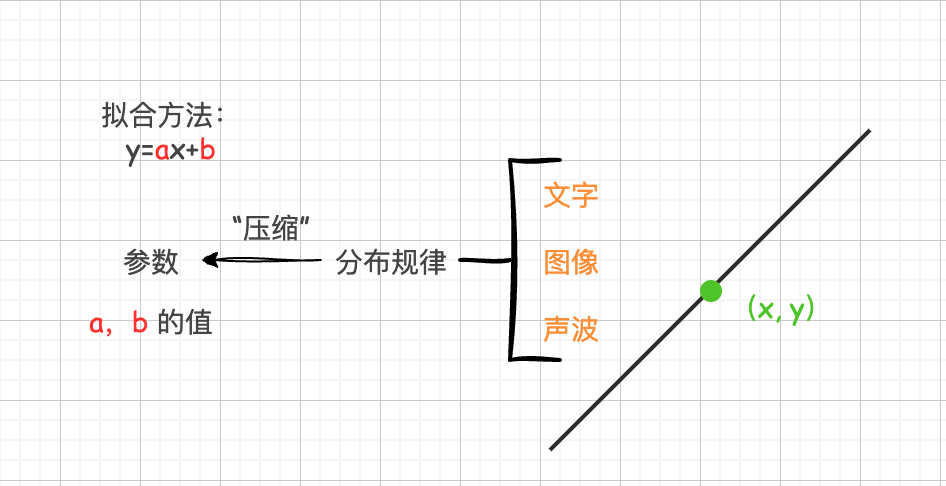
而文字、图像和声音的规律显然比一条直线复杂得多。因此,拟合这些复杂规律所需的方法也更加复杂,涉及自注意力机制、Embedding词嵌入、反向传播算法、Transformer架构等高级技术。为了更准确地捕捉这些复杂的分布规律,需要使用更多的参数,通常需要百亿、千亿甚至更多的参数量。然而,本质上,它与用一个简单的公式去拟合一条直线的思想是相同的。
正如神经网络之父、图灵奖获得者 Geoffrey Hinton 早前对 GPT-3 的一番评论:

“鉴于 GPT-3 在未来的惊人前景,可以得出结论:生命、宇宙和万物的答案,就只是 4.398 万亿个参数而已。”
训练大模型
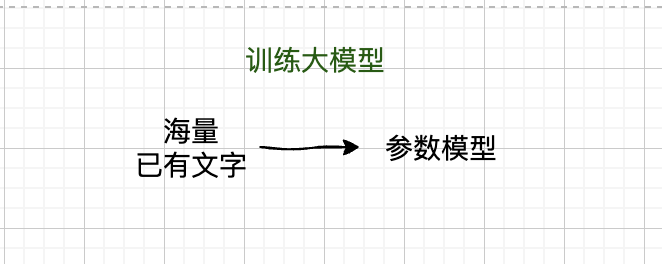
训练大语言模型的过程,就是通过 海量的现有文字 去推导出 最适合的模型参数。
这就像是已知的两个点 (1,1) 和 (2,3) 的坐标,以及直线方程表达式 y = ax + b,根据这些信息来推导出 a 和 b 的值。
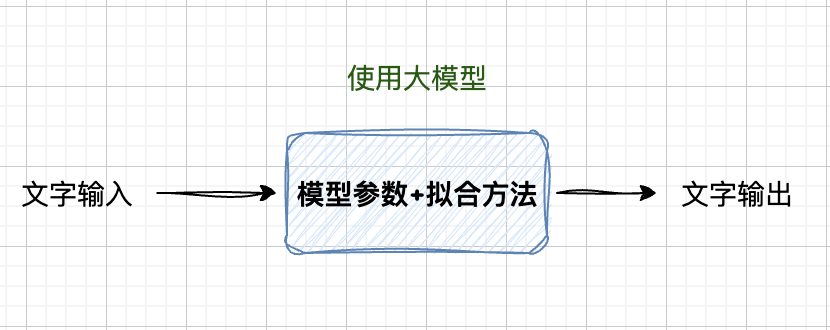
使用大模型
而使用大模型的过程其实就是输入一些文字,经过模型参数和拟合方法的计算,输出另外一些文字。
你可以把他理解为,已经知道了直线方程表达式 y = ax + b 以及 参数 a 和 b 的值(比如 a = 0.5,b = 0.5),然后给定一个 x 坐标(比如 x = 5),让你计算对应的 y 值,或者给你一个点 (1,1),让你找到它附近的另外一个点。
把大模型装进Excel表格
电子表格的魔法
即使是使用Excel表格,也能制作出一个大模型。事实上,Github上有一个非常有趣的项目,名为 Spreadsheet Is All You Need。简单来说,这个项目把 GPT2 的全部推理过程塞进了一张电子表格里。没错,就是我们平时用来记账的电子表格,这简直太疯狂了!
Github地址:https://github.com/ianand/spreadsheets-are-all-you-need
用 Excel 来理解 GPT 模型?作者发现变换器(transformer)的内部机制其实就是一系列矩阵计算的巧妙排列。于是,他突发奇想:既然这些计算不复杂,为什么不试试用电子表格来实现整个过程呢?结果真是大开眼界——他真的成功了!
忘掉 Python,电子表格才是你需要的全部工具。
这个表格包含了 GPT 模型的所有关键组件,包括嵌入(embedding)、层归一化(layer norm)、自注意力(self attention)、投影(projection)、多层感知机(MLP)、Softmax 和 Logits。整个结构基于 Andrej Karpathy 的 NanoGPT,虽然只有大约 85000 个参数,但足够复杂,同时不会让你的电脑崩溃。
而且,这个项目是字符级的预测系统,每个 token 是一个字符,只对字母 A/B/C 进行标记化。这样设计既能帮助理解模型,又不会过于复杂。
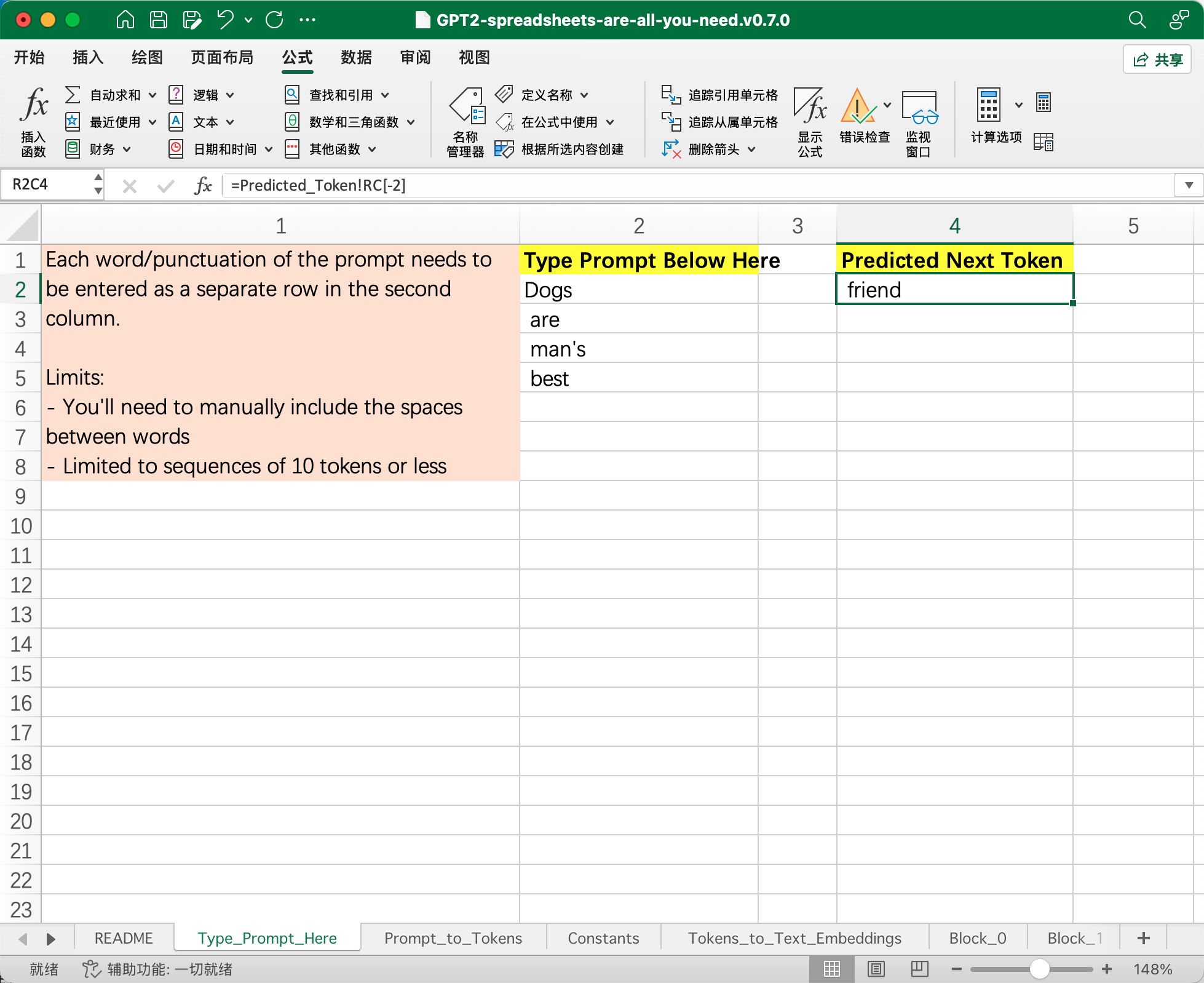
如何使用?
我们在左侧输入 Dogs are man's best,经过模型计算之后它就会预测出下一个单词是 friend 并在右侧输出:
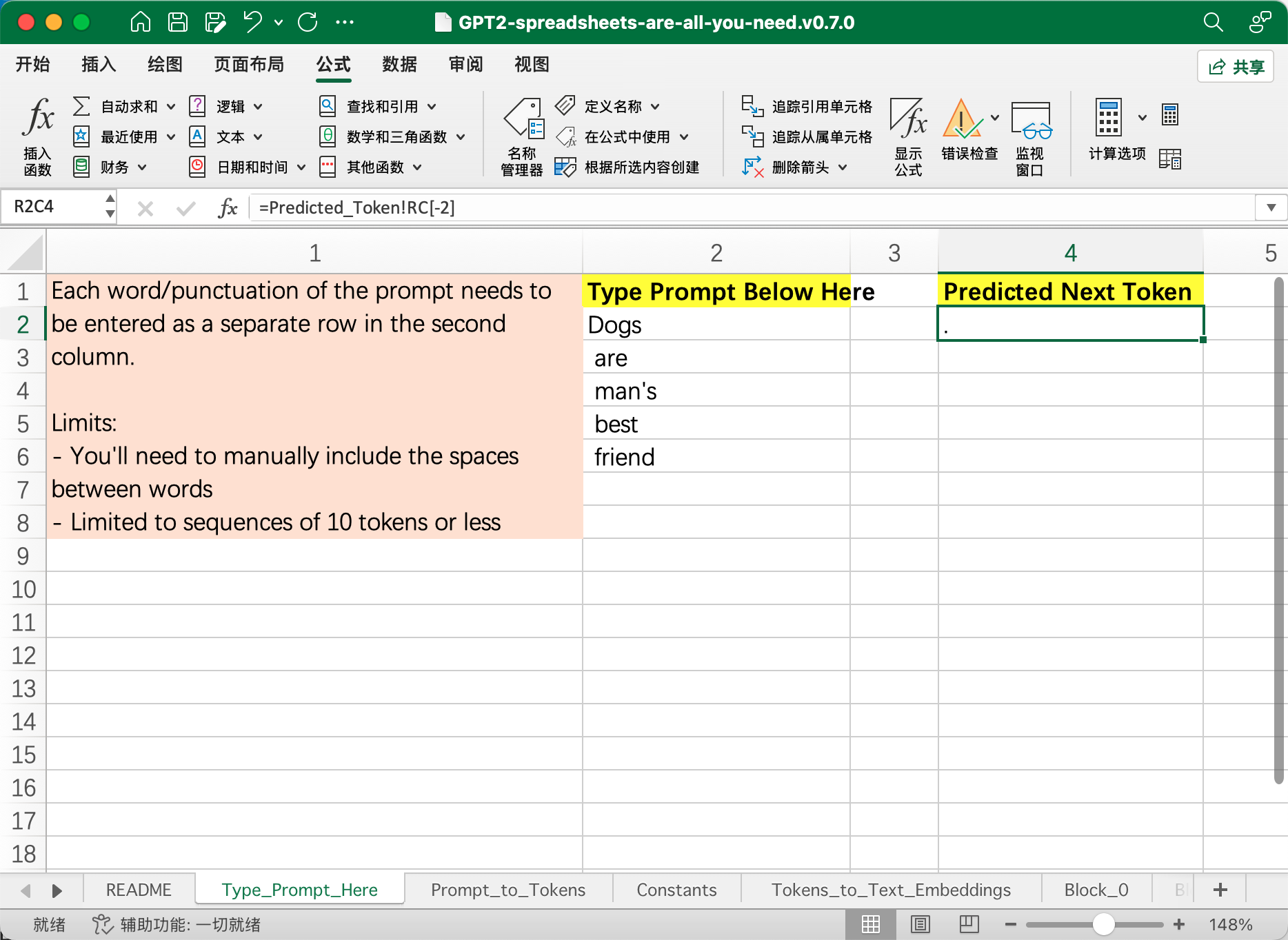
继续在左侧输入 friend,它就能预测出下一个字符是句号 . :
(关于更多细节,包括表格中每个Sheet的含义及其背后的工作原理,限于篇幅,将在后续专门的文章中详细解析。)
这个项目最酷的地方在于,它完全颠覆了我们对电子表格的传统认知。谁能想到,平时用来做财务报表的工具竟然也能用来解析前沿的AI技术?这不仅是一种创新,更是一种思维方式的转变。它让我们意识到,科技的边界比我们想象的要广阔得多。
通过使用电子表格,任何人,即使是非开发人员,都可以探索并了解大语言模型是如何在后台工作。
总之,如果你对 AI 和 LLM 感兴趣,并且喜欢动手实践,这个项目绝对值得一试。拿起你的电子表格,开始探索GPT的奥秘吧!


