行云流水间:队列的妙用与任务分配(python queue)

行云流水间:队列的妙用与任务分配(python queue)
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/78bee7de.html
你好,我是测试蔡坨坨。
众所周知,在编程的世界里,数据结构作为程序员的一把利剑,能够帮助我们高效地处理和组织数据。数据结构主要分为线性结构和非线性结构两类。常见的数据结构包括数组、链表、栈、队列、树和图等。每种数据结构都有其独特的特点和适用场景,正确选择和应用能够极大地提高程序的效率和性能。
因此,本篇我们就来讲讲queue,也就是队列。
队列是一种简单而有序的线性数据结构,通常情况下遵循FIFO(先进先出)原则,即最先放进去的数据会被最先取出。当然,偶尔我们也会用到它广义的意思,一个可以逐个往里放数据,然后按照一定的顺序输出的数据结构,例如PriorityQueue(优先级队列)。简而言之,队列只需支持两个功能,也就是放和拿。
以下例子利用Python内置的queue模块构建了一个队列,将0-9按顺序依次放入队列中。然后,检查队列是否为空,如果不为空,则将队列中的数据一个一个取出并打印输出:
1 | # author: 测试蔡坨坨 |
运行结果就是按顺序打印0-9,这就是所谓的FIFO,数据会按照进入队列的顺序被取出,就好像大肠,一边进东西,一边出东西。
queue数据结构有着广泛的应用,其中最常见的就是用来有序地安排任务。
在生活中,有许多类似队列的场景,例如游乐园售票窗口卖票。如果没有队列的存在,人们可能会直接涌向售票窗口,就会造成售票窗口拥堵,有一堆人吵着要买票,导致售票本身的效率下降,还有可能身材弱小的人永远也买不到票,因为是谁最强壮,谁挤得赢谁先买票。
因此,队列的发明解决了这个问题,按照先来后到的原则,一个一个的去售票窗口买票。如果发现队列太长,我们可以开设更多的售票窗口;反之,队列较短时,可以减少窗口数量。这样一来,每个人都有公平的机会购票,避免了早来者却买不到票的情况发生。
在编程中,任务来一个解决一个不就完事了吗,要queue有什么用呢?事实上,队列的有序性经常是保证我们算法正确执行的基础。
举一个常见的例子:BFS(广度优先搜索)算法。
1 | # author: 测试蔡坨坨 |

在定义了一个简单的二叉树后,我们想要使用广度优先搜索。通常最常见的做法是创建一个队列(queue),用于确定当前应该搜索哪个节点。由于队列的先进先出性质,对于每个节点,我们首先搜索自身,然后搜索左节点,再搜索右节点,从而保证了广度优先搜索的顺序。
如果没有使用队列来确保任务的有序性,很可能会导致算法变为深度优先搜索。因此,一个先进先出的队列在实现广度优先搜索算法中扮演了重要角色。
有些同学可能会质疑,为什么不能直接使用列表(list)呢?从逻辑上讲,当然也可以。事实上,使用列表重写后会得到与使用队列相同的结果。
1 | # author: 测试蔡坨坨 |
然而,相较于队列(queue),列表(list)存在两个严重的问题。
首先是性能方面的问题。使用列表的pop(0)操作的时间复杂度是O(N),因为每次取出一个数据后,列表中后面的数据都需要向前移动一个单位。而队列的put和get操作都是常数时间复杂度,即O(1)。当然,这里指的是一般情况下的实现,你也可以实现出一个queue不是常数时间的,因为queue本身是一个抽象的数据结构,可以由多种其他数据结构实现,但在Python和其他大多数语言中,内置queue写入和读取操作都是O(1)的。
第二个问题涉及多线程方面,主要与阻塞和线程安全有关。
以producer consumer model(生产者-消费者模型)来举栗说明。
什么是producer consumer model?
生产者-消费者模型是一个非常简单而常见的概念。在这个世界上有任务的产生者,还有任务的完成者。举栗来说,在工作中场景中,老板布置任务,他们就是任务的产生者producer,员工A负责任务1,员工B负责任务2、3,员工A和员工B最后把任务一凑,完成了老板布置的全部任务,员工就是任务的完成者consumer。
在实际应用中,生产者和消费者的比例可能各不相同,有可能是1:100,也有可能是100:1。这时,队列就起到了关键作用,作为任务的生产方,他们无需考虑把任务交给谁去解决,只需将任务放到queue中即可。同样,作为任务的完成者,也无需考虑应该解决谁的任务,只需要从queue中获取任务即可。
这种模型通过队列实现了生产者和消费者之间的解耦合,使得系统更加灵活和可扩展。
例如以下栗子:
1 | # author: 测试蔡坨坨 |
作为producer,只需要把0-9扔到queue里,作为consumer,拿到一个数就将其打印出来。

程序执行后,虽然0-9都被打印出来了,但它们的顺序并不是按照递增顺序。这是因为我们只能保证任务被开始执行的顺序,而不能保证任务完成时的顺序。
在实际应用中,不同任务的完成时间可能不同。例如,假设有10个任务,其中5个分配给consumerA,另外5个分配给了consumerB,这可能导致任务分配不均衡的情况发生。一个人拿到的5个可能很简单,另外一个人拿到的5个可能很复杂。而这种利用队列来分配任务,并在一个任务完成后再获取另一个任务的方式,实际上是一种负载均衡的策略。
在这里,q.get()是一个阻塞操作,即如果队列中没有任务,它会一直等待,直到队列中有任务为止。这是一个非常有用的特性,有任务你就做,没任务你就歇着。而这种阻塞能力是list所没有的,要想让list也具备类似的能力,虽然可以加入条件判断,list里有东西我就拿,没有东西我就不拿,这么做看似合理,但实际上会引发一系列问题。
1 | def consumer(ls): |
这么做会有什么问题呢?
这种方法会导致CPU资源的浪费。因为如果列表为空,条件判断会一直循环检查,实际上是一直在做操作的。即使加入sleep操作,也很难确定合适的睡眠时间。睡眠时间太短会导致CPU资源浪费,而睡眠时间太长则可能会导致任务积压。
1 | def consumer(ls): |
显然,使用列表(list)不具备队列的阻塞特性,因此缺乏灵活性。
另外一个问题是线程安全性。在单线程环境中,只要列表不为空,就可以直接取出元素。但在多线程程序中,在进行完list的非空判断后,有可能会把操作移交给另外的线程,而另外一个线程也恰恰刚好完成了这个判断,于是就有可能在list中只有一个元素的情况下,两个线程同时去执行ls.pop(0)取那个唯一的元素,就会有一个线程在pop的时候发现list里面没有东西,从而产生异常。
要想让程序正常工作,还需要在这里添加锁。相比之下,使用队列的写法更加简单和可靠。
当你运行程序时,你可能会发现一个问题:程序没有自动停止,而是一直处于运行状态。这是因为两个消费者线程都被阻塞住了,它们仍然等待从队列中获取任务,但队列中再也没有新的任务产生了,因为producer()函数已经结束了。
在默认情况下,Python进程会等待所有线程都结束后再退出。因此,这个程序会一直停留在运行状态。
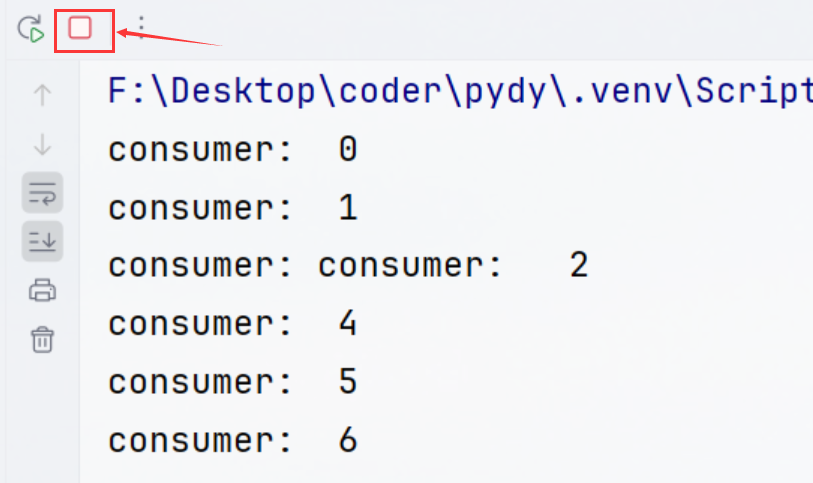
这里可能有小伙伴会想到用Thread的daemon=True参数。但实际上,运行后发现什么都没打印出来。因为生产者线程会非常迅速地完成任务分配,而消费者线程还来不及处理任务,主线程就已经结束了,导致所有线程都被关闭。
1 | # 创建并启动生产者、消费者线程 |

我们想要达到的效果是所有的任务都完成后,线程再结束。那我就去判断下queue是否为空,如果为空再结束线程,这样是否可行?
1 | while not q.empty(): |
两个问题,一是无法确定等待多长时间合适,二是queue里面的任务为空并不代表任务就全部完成了,只能说明任务被领取完成了。当consumer拿完最后一个任务的时候,queue就空了,此时可能只是拿到任务,而任务还没有做完,线程就结束了。
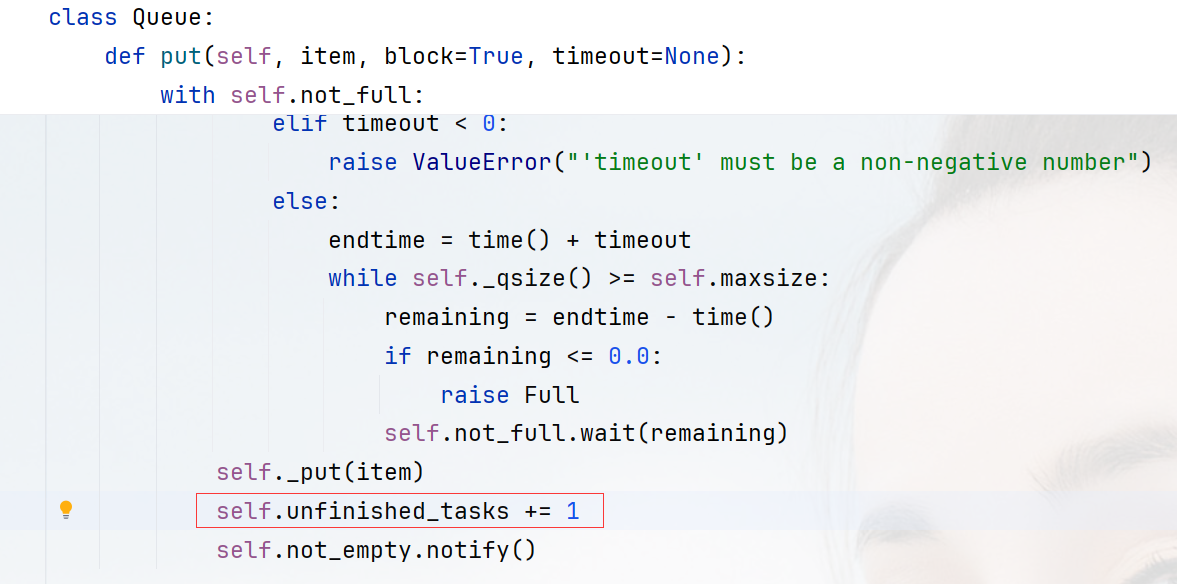
也就是说只有consumer知道什么时候任务完成,因此,Python的queue提供了一个特殊的标记方式task_done(),用于标记任务的完成。
1 | # author: 测试蔡坨坨 |
当producer往queue里面放一个任务的时候,Python会在这个queue的内部计数器里面加1,而每次运行task_done()的时候会把这个计数器减1。这样consumer在每次完成任务后,只要调用一下task_done()函数就可以告诉queue有多少任务已经完成了。然后,在主线程中使用q.join()方法等待队列中的所有任务都被标记为完成,join()函数会阻塞在这里,直到q的task_done()和put()一样多。

至此,我们完成了一个最基础的Python生产者消费者模型。
除了最核心的FIFO队列外,Python中的队列模块还提供了其他类型的队列,如LifoQueue(后进先出)和PriorityQueue(优先级队列)。
这些队列类型在不同的场景下有着各自的用途和优势,可以根据具体需求选择合适的队列类型来实现生产者消费者模型。
1 | # author: 测试蔡坨坨 |
1 | # author: 测试蔡坨坨 |
总的来说,队列是一个非常简单而实用的数据结构。
Python的Queue模块支持多线程之间的数据交换和同步,是一种线程安全的数据结构。它可以被多个线程安全地访问和操作,能够实现线程间的安全数据传递和同步。清楚了其中的原理后,我们在学习其他编程语言中的多线程编程也会更加容易。
由于篇幅关系,其他类似的知识点我们可以在以后的文章中继续探讨。









